When Tim Berners Lee talks about how he designed the web, he uses an analogy from physics, describing his process as a quest to find “fundamental laws” which can generate a desired system:
当 Tim Berners Lee 谈到他如何设计网络时,他使用了一个来自物理学的类比,将他的过程描述为寻找能够生成所需系统的”基本法则”的探索:
One of the beautiful things about physics is its ongoing quest to find simple rules that describe the behavior of very small, simple objects. Once found, these rules can often be scaled up to describe the behavior of monumental systems in the real world.
If the rules governing hypertext links between servers and browsers stayed simple, then our web of a few documents could grow to a global web. The art was to define the few basic, common rules of “protocol” that would allow one computer to talk to another, in such a way that when all computers everywhere did it, the system would thrive, not break down.
Tim Berner’s Lee, 2000, “Weaving the Web”
物理学的美妙之处在于它不断寻找描述极小、简单物体行为的简单规则。一旦发现这些规则,通常就可以将其扩展到描述现实世界中宏大系统的行为。
如果管理服务器和浏览器之间超文本链接的规则保持简单,那么我们最初的几个文档网络就可以发展成为一个全球性的网络。这门艺术就在于定义几个基本的、通用的”协议”规则,使一台计算机能够与另一台计算机对话,以至于当世界各地的所有计算机都这样做时,整个系统能够蓬勃发展而不会崩溃。
Tim Berner’s Lee,2000年,《编织万维网》
I like this description of design as a quest to discover a simple set of primitives, a small alphabet for generating a system. To paraphrase Gall’s Law:
Simple rules produce complex behavior. Complex rules produce stupid behavior.
我喜欢这种将设计描述为探索简单原语集合的方式,这些原语就像是生成系统的小型字母表。用 Gall 定律的话来说就是:
简单的规则产生复杂的行为。复杂的规则产生愚蠢的行为。
What if we applied this lens to designing tools for thought? What are some examples of simple features with extremely broad ranges of motion? I’d like to put forward one candidate…
如果我们用这种视角来设计思考工具会怎样呢?有哪些简单但应用范围极广的功能特性呢?我想提出一个候选者……
Links.
链接。
A surprising number of other features can be expressed in terms of links.
令人惊讶的是,许多其他功能都可以用链接来表达。

What is a tag? What is its structure? What is its function?
什么是标签?它的结构是什么?它的功能是什么?
When you tag something, it gets added to a collection of other things with the same tag. So, this is a one-to-many relationship, where one tag points to many pages.
当你给某物贴上标签时,它就被添加到具有相同标签的其他事物的集合中。因此,这是一种一对多的关系,一个标签指向多个页面。

Let’s think about a link. Many pages can point to a single page. Many-to-one. One-to-many. So, we could achieve tagging with links by listing all backlinks to a given page. Tags are just backlinks to pages that don’t exist.
让我们思考一下链接。多个页面可以指向单个页面。多对一。一对多。因此,我们可以通过列出指向特定页面的所有反向链接来实现标签功能。标签其实就是指向不存在页面的反向链接。
Folders are a place to put things. Like most of the desktop paradigm, folders use a familiar object borrowed from the office as a metaphor to communicate an abstract relationship. You put multiple documents into a paper folder for filing, you put multiple documents into a digital folder for filing. Object metaphors are powerful, both because they leverage something familiar to introduce something new, and because they lean into our natural cognitive strengths for spatial reasoning and object manipulation.
文件夹是用来存放东西的地方。与大多数桌面范式一样,文件夹借用了办公室中熟悉的物品作为隐喻,来传达一种抽象的关系。你把多个文档放入纸质文件夹进行归档,同样也把多个文档放入数字文件夹进行归档。物品隐喻之所以强大,一方面是因为它们利用熟悉的事物来引入新事物,另一方面是因为它们依赖于我们在空间推理和物体操作方面的天然认知优势。
Hmm, many documents, one folder. It seems that underneath this object metaphor is another one-to-many relationship. So, a folder could be expressed in terms of a page full of links.
嗯,多个文档,一个文件夹。看来在这个物品隐喻下面还隐藏着另一种一对多的关系。因此,文件夹可以表示为一个充满链接的页面。
What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention, and a need to allocate that attention efficiently among the overabundance of information sources that might consume it.
Herbert Simon
信息消耗的是什么,这一点相当明显:它消耗的是接收者的注意力。因此,信息的丰富造成了注意力的匮乏,并产生了在可能消耗注意力的过多信息源中高效分配注意力的需求。
赫伯特·西蒙
Social media, search, spam, recommendations — when faced with an abundance of information, we often find ourselves needing to separate wheat from the chaff. Many systems reach for stars, hearts, upvotes, and downvotes as quick fixes for user-generated quality signals. But what if we just used links?
社交媒体、搜索、垃圾信息、推荐——当面对海量信息时,我们常常需要去粗取精。许多系统采用星级、心形、点赞和踩等方式作为用户生成的质量信号的快速解决方案。但如果我们只使用链接呢?
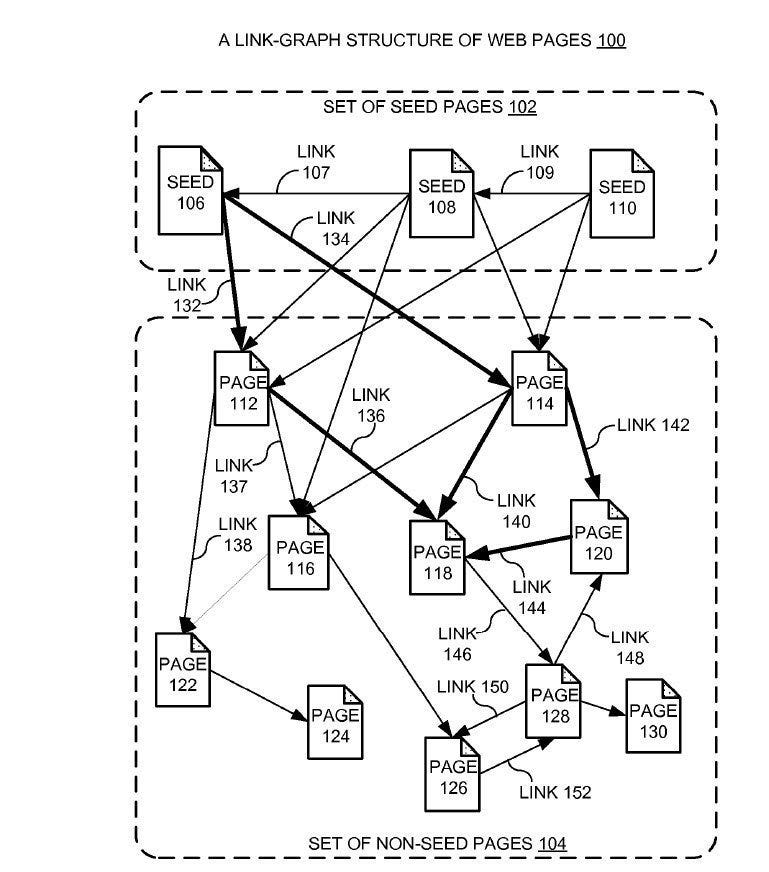
Inbound links can be used as a signal of quality. People are more likely to link to things that matter, and less likely to link to things that don’t. Sum up the backlinks to a page and you have a quality signal. This is the key insight behind Google Pagerank.
入站链接可以作为质量的信号。人们更倾向于链接到重要的内容,而不太可能链接到不重要的内容。将指向一个页面的反向链接总和起来,你就得到了一个质量信号。这是 Google PageRank 背后的关键洞见。
Comments are one of the core interaction primitives of today’s web. I can comment on your Facebook post, your Google Doc, your blog.
评论是当今网络核心交互原语之一。我可以在你的 Facebook 帖子、Google 文档或博客上发表评论。
What is a comment? What is its structure? What is its function? It’s a bit of content that is conceptually related to a parent post. We could say that the comment points to the post, or something in the post. That’s a directional relationship.
什么是评论?它的结构是什么?它的功能是什么?评论是一段在概念上与父帖子相关的内容。我们可以说评论_指向_帖子,或帖子中的某些内容。这是一种定向关系。
Links also point to something. They describe a directional relationship. It’s not much of a leap to consider an inbound link a comment on the thing it links to. If we implement some form of transclusion, we can express comments in terms of links. In fact, WordPress already does this with Pingbacks.
链接也_指向_某些东西。它们描述了一种定向关系。将入站链接视为对其所链接内容的评论并不是一个很大的跨越。如果我们实现某种形式的嵌入,我们就可以用链接来表达评论。事实上,WordPress 已经通过 Pingbacks 实现了这一点。
Outliners are tools for thought that conceive of documents as a hierarchy, or tree, or nested bulleted list. They’re one of those simple ideas, like spreadsheets that have an almost inexhaustible range of applications.
大纲工具是一种思考工具,它将文档视为层级结构、树状结构或嵌套的项目符号列表。它们是那些简单却应用范围几乎无穷无尽的想法之一,就像电子表格一样。
Outliners have a rich and interesting history, from Dave Winer’s outliner programs for command line and Mac Classic, through to today’s Roam Research.
大纲工具有一个丰富而有趣的历史,从 Dave Winer 的命令行和 Mac Classic 的大纲程序,到今天的 Roam Research。
So, but what is an outliner? What is its structure? What is its function? An outliner lets you break a document up into discrete nodes, nest those nodes under other nodes, hide branches, focus in on branches. The structure formed by an outliner is a tree, with parent and child nodes.
那么,什么是大纲工具?它的结构是什么?它的功能是什么?大纲工具允许你将文档分解为离散节点,将这些节点嵌套在其他节点下,隐藏分支,聚焦在分支上。大纲工具形成的结构是一个树状结构,有父节点和子节点。
In an outliner, one parent may have many children. One-to-many. Links again. We can express an outliner in terms of links by nesting inbound links underneath the document they point to. So an outliner could be thought of as one view over a network of linked documents.
在大纲工具中,一个父节点可能有多个子节点。一对多。又是链接。我们可以通过将入站链接嵌套在它们所指向的文档下方来用链接表达大纲工具。因此,大纲工具可以被视为链接文档网络的一种视图。
Semantic triples are one of those ideas you run into if you poke around the “tools for thought” space long enough. A semantic triple is a simple idea with some powerful properties. The basic idea is to construct a network made up of:
语义三元组是你在”思考工具”领域探索足够长时间后会遇到的想法之一。语义三元组是一个简单但具有强大特性的概念。其基本思想是构建一个由以下元素组成的网络:
Subject - Predicate - Object
主语 - 谓语 - 宾语
For example, “Xerxes is the parent of Brook” can be expressed as a triple:
例如,“Xerxes 是 Brook 的父母”可以表示为一个三元组:
Xerxes - Parent - Brook
Xerxes - 父母 - Brook
Objects can themselves be subject-predicate-object triples, so you can build up complex networks of relationships this way.
宾语本身也可以是主语-谓语-宾语的三元组,因此你可以用这种方式构建复杂的关系网络。
Triples allow computers to do complex automated reasoning. You can even use them to derive relationships that aren’t explicitly stated. You know those answer cards that appear in Google searches? Those are largely constructed from Google Knowledge Graph, a giant network of semantic triples.
三元组使计算机能够进行复杂的自动推理。你甚至可以用它们来推导出未明确陈述的关系。你知道在 Google 搜索中出现的那些答案卡片吗?它们主要是由 Google 知识图谱构建的,这是一个巨大的语义三元组网络。
Triples are often expressed in terms of special formal languages like TURTLE or Datalog. Here’s how I might jot down that Xerces is a parent of Brooke and Brooke is a parent of Damocles using Datalog:
三元组通常用特殊的形式化语言表示,如 TURTLE) 或 Datalog。以下是我如何用 Datalog 记录 Xerces 是 Brooke 的父母,而 Brooke 是 Damocles 的父母:
parent(xerces, brooke).
parent(brooke, damocles).
This can get old fast. Writing formal relationships by hand is ok for narrow domains, but it’s not exactly the most natural thing to reach for when trying to express ideas.
这种方式很快就会变得过时。手动编写形式化关系对于狭窄的领域来说还可以,但当试图表达想法时,这并不是最自然的方式。
So, knowledge graphs are tremendously useful for computers, but not so fun to write by hand. If you ask me, Semantic Web efforts have repeatedly stubbed their toe on this mismatch between symbolic alignment and the messy, emergent, imprecise, human process of knowledge construction.
因此,知识图谱对计算机来说非常有用,但手动编写并不那么有趣。如果你问我的看法,语义网的努力一再在符号对齐与混乱、涌现、不精确的_人类_知识构建过程之间的不匹配上碰壁。
But wait. What is a triple? What is its structure? What is its function?
但是等等。什么是三元组?它的结构是什么?它的功能是什么?
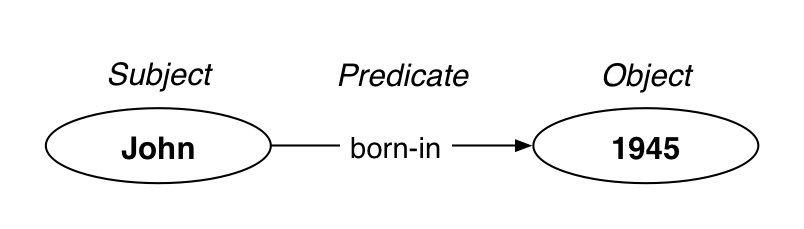
It seems a triple is a link between two things, through a predicate. Here is yet another thing we can reimagine through the mechanism of links.
看来三元组是通过谓语将两个事物连接起来的链接。这又是一个我们可以通过链接机制重新想象的概念。
A hyperlink is a triple where the subject is the page, the predicate is the link text, and the object is the thing being linked to.
超链接是一个三元组,其中主语是页面,谓语是链接文本,宾语是被链接的对象。
Better yet, it’s organic. This knowledge graph is constructed from things I would do anyway. I create a link because it solves my problem as an author of pointing you, the reader, to a concept. This good-enough alignment between user goals and computer goals is one reason the regular web succeeded where the semantic web failed.
更好的是,这是有机的。这个知识图谱是由我本来就会做的事情构建的。我创建链接是因为它解决了我作为作者指引你这个读者到某个概念的问题。用户目标和计算机目标之间的这种足够好的对齐是普通网络成功而语义网失败的原因之一。
Topic modeling is a range of machine learning techniques for deriving abstract topics from a collection of documents using statistical analysis. I put in a collection of Subconscious newsletters, and topic modeling tells me they’re about tools for thought, cybernetics, the web, computing, distributed systems, etc. Pretty cool.
主题建模是一系列机器学习技术,用于通过统计分析从文档集合中提取抽象主题。我输入了一系列 Subconscious 通讯,主题建模告诉我它们是关于思考工具、控制论、网络、计算、分布式系统等的。相当酷。
So, ok, you might still want topic analysis, but following on from our observation that we can use links as knowledge graphs, we can also use links as quick-and-dirty topic models.
所以,好吧,你可能还是想要主题分析,但根据我们观察到可以使用链接作为知识图谱,我们也可以使用链接作为快速而粗略的主题模型。
If we consider each page to be a topic, then then links offer a pretty good map of topics within a page. Pull out a list of links from a page, and you approximately have the topics for the page. Collect all the links across pages, rank them by frequency, and you have a sense of the most frequently addressed topics within the collection.
如果我们将每个页面视为一个主题,那么链接就为页面内的主题提供了一个相当不错的映射。从一个页面提取链接列表,你就大致得到了该页面的主题。收集所有页面的链接,按频率排序,你就能感知到整个集合中最常涉及的主题。
It is my belief that this new ability to represent ideas in the fullness of their interconnections will lead to easier and better writing, easier and better learning, and a far greater ability to share and communicate the interconnections among tomorrows ideas and problems. Hypertext can represent all the interconnections an author can think of, and compound hypertext can represent all the interconnections many authors can think of, as we shall see.
Ted Nelson, 1982, “Literary Machines”
我相信,这种以全面互联的方式表达思想的新能力将会带来更轻松、更优质的写作,更轻松、更有效的学习,以及更强大的能力来分享和交流明天的思想和问题之间的相互联系。超文本可以表示一个作者能想到的所有互联,而复合超文本可以表示许多作者能想到的所有互联,正如我们将要看到的那样。
Ted Nelson,1982年,《文学机器》
Links aren’t the only way—I don’t want to be totalizing here—but they are something special. It’s rare to discover a simple mechanism with such broad and expressive range of motion.
链接并不是唯一的方式——我不想在这里过于绝对化——但它们确实很特别。很少能发现一种具有如此广泛和富有表现力的运动范围的简单机制。