卷首语
本期周刊的标题来自《长期游戏的惊人力量》这篇文章,本周五在阮一峰老师的周刊上读到,觉得很有价值
为什么要选择长期游戏?
- 长期游戏是正确的,因为大多数人都会选择短期游戏,想要获得超过大多数人的超额回报,就需要玩长期游戏
- 长期游戏是困难的,因为你需要先承受当前的痛苦,才能让未来更容易一些。但容易的时候什么时候到来,也是一个未知数
- 长期游戏是简单的,因为它不需要复杂的策略或技巧,而是需要持续的、日常的、看似微小的努力
写代码和写文章也是类似的长期游戏,需要耐心和持续的努力,虽然过程可能很艰难,也未必能够一定成功,但却是一条正确的道路

Prompt
Under the infinite canvas of the nocturnal sky, a solitary figure is silhouetted against the cosmic splendor of the Milky Way. Perched on a rugged peak, the individual is immersed in the tranquility of nature, contemplating the vastness above. The celestial display of countless stars and the brilliance of the galaxy stretch into the distance, while the horizon glows softly with the last whispers of the sunset. This moment captures the sublime connection between humanity and the cosmos, a reverent pause in the majesty of the universe.
内容推荐
【案例】2013 年 Notion 的使命和目标
在 7 月中旬的时候,Notion 的创始人 Ivan Zhao 宣布 Notion 已经达到了 1 亿个用户,他在 Twitter 上分享了从 2013 年到 2024 年的整个成长历程,其中有一条是 2013 年关于 Notion 使命和目标的介绍 ppt
ppt 封面的第一句话是:我们塑造了我们的工具,然后我们的工具塑造了我们(We shape our tools, and thereafter our tools shape us)
- 我们根据需求和目标设计和制造工具,帮助我们完成特定任务,这是创造的过程
- 一旦工具和技术被创造出来,我们会使用这些工具来改善生活和工作,这些工具也在潜移默化中改变我们的人类行为、思维方式和社会结构
- 这句话是 Notion 创造的最初动力,旨在实现 70 年代的一个愿景:软件可以增强人的智力

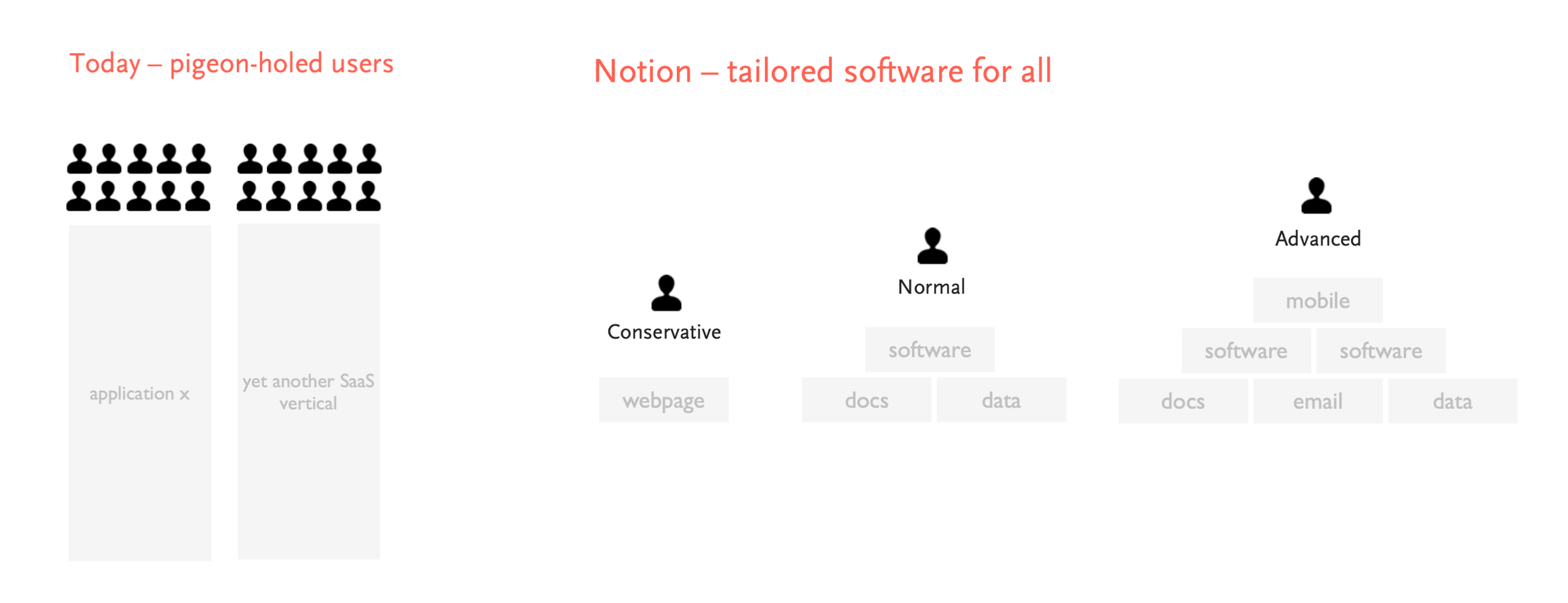
第二张是 Notion 的愿景:软件民主化,让非程序员也能够创建和定制软件应用,而不仅仅是使用现成的软件
- 从下面的人数比例可以看到,程序员有两百万人,但却有八千万的知识工作者和超过两亿的互联网用户
- 所以 Notion 并不仅仅想做一个知识管理工具,如何让八千万的知识工作者和两亿用户拥有构建程序的能力,才是 Notion 最终的目标

接下来的三张图,就是 Notion 对于如何实现“软件民主化”愿景的方式
方式一:构建一个不需开发人员介入,就能直接输出产物的环境
- 在 Notion 之前,设计者需要通过原型图片,和客户与开发人员反复沟通,才能得到最后的应用
- 而通过 Notion,设计者可以在和客户沟通之后,直接制作应用

方式二:为所有人量身定制的软件
- 在以前,用户只能找到一个又一个的应用
- 而 Notion 则可以针对不同的用户,为他们提供量身定制的软件
- 比如基础用户用 Notion 构建一个基础的个人介绍页面
- 而高级用户则可以通过 Notion 构建一个客户管理数据库、一个项目管理应用等等
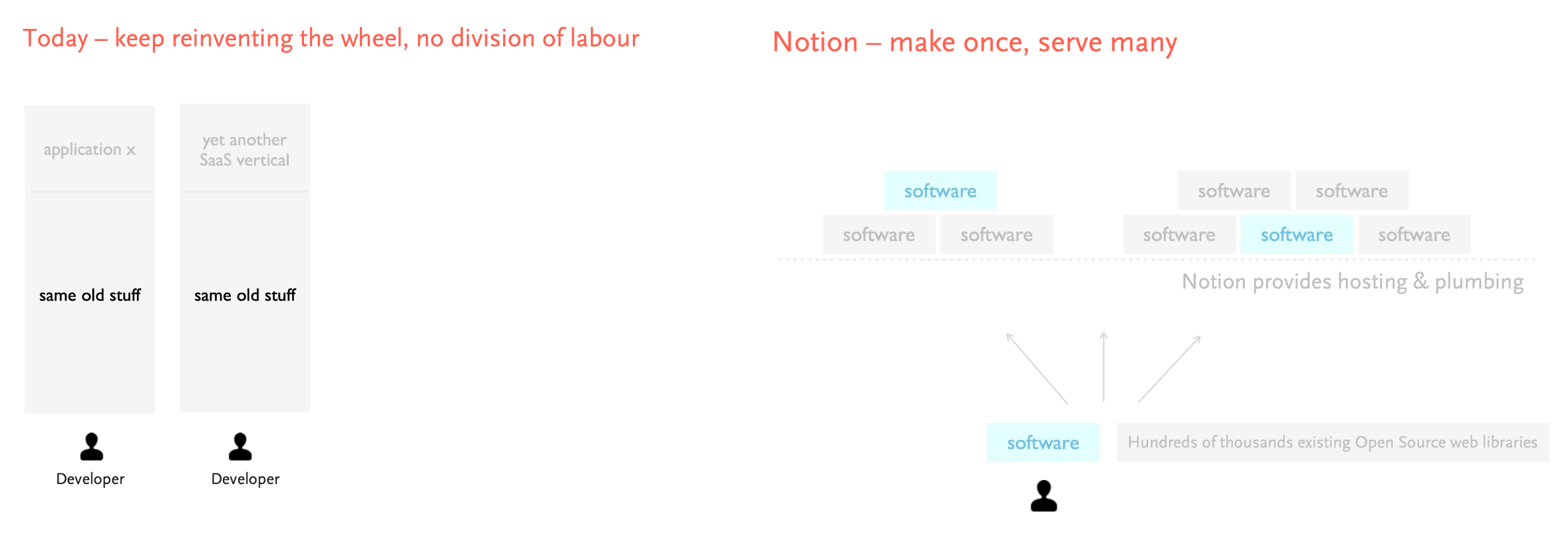
方式三:一次制作,多次使用
- 在 Notion 之前,开发人员在不同的应用之间,不断地重复相同的工作
- 而借助 Notion 和非常多的开源模板库,可以达到只制作一次,就能够重复使用的效果
从现在的角度回看,Notion 以 block 为最小单位的模块,对于 Page(页面) 和 Database(数据库) 的高度抽象,加上最近发布的直接生成网站的功能,Notion 真的在一步一步地实现当时的使命
如何成就一个伟大的产品?引用创始人 Ivan 的原文内容:
我们做这一切不仅是为了构建一个软件,而是想按照我们的价值观构建一些伟大的东西,让下一代不仅只是使用,还能热爱
引用乔布斯的话来说就是,「给人类留点有价值的东西」(put something back to the humanity)
这也是一个关于长期游戏的故事
相关链接
【创业】营销大师 Dan Lok 的成功经验
我是在王川的一篇文章中了解到 Dan Lok,之前并不了解这个人,去看了一下他的官网,很有“华尔街之狼”的风格
Dan 出生在香港,现在居住在温哥华的八零后营销大师,他在 27 岁的时候就已经年少成名,财务自由。在读他的自我介绍的时候,在他成功之前的三个小故事给我留下很深的印象
第一个小故事是在 Dan 成功之前,他尝试了十三次不同的创业点子,但最后却连续失败了十三次,直到第十四次才成功
创业也像是一个长期游戏,不断的尝试,不断的积累经验,最终总会成功,只是这个过程的时间长短没有办法计算。每次失败的打击,都会让人觉得这是最后一次失败了,是“黎明前最黑的时候”,只要熬过去就好了,但现实可能是“黑夜才刚刚开始呢”
我觉得最后的创业失败,要么是自己累了,不想再尝试了;要么是负债累累,没有办法再继续创业下去了,所以从这个角度思考:
- 留在场上很重要,只要还能够继续尝试,就还留有成功的机会
- 心态可能比能力重要,在一次次被失败打击之后,是不是还能够拥有继续开始的勇气
第二个小故事是 Dan 在写自己第一封行销信(类似产品服务宣传文案)的时候, 每一次写好交给导师,导师都会回复他:烂透了,再写一次。直到反复六七次之后,导师才点头认可
一年后导师偷偷告诉 Dan:其实当初你写的第一封营销信就已经相当不错了,但我觉得我要挑战你的能力极限。第二次你再来,你以为你写出来的已经是你的最佳作品,但事实上你认定的最佳,跟你实际上能达到的最佳状况,往往有一段不小的差距。所以当你要磨练一项技巧,要能够认知到自己还没有出尽全力这件事,并做出相对应的改变,才能够有所进步
“烂透了,再做一次” 不一定是坏事,很多时候我们总是会以为自己已经竭尽全力了,但实际上离自己能力的极限还有很大距离。再试一次,才能离极限更近一点
第三个小故事是 Dan 在独立工作的时候,最开始的报价是 1000 元,但因为只有他一个人,1000 元的报价很难养活 Dan 的家庭
导师在这个过程中,建议 Dan 的报价直接加倍,从 1000 元到 2000 元,再到 4000 元,最后到 8000 元。这个过程开始很困难,总是会觉得高报价会让自己的客户流失,但实际尝试之后,才能了解到实际的情况
想要赚更多的钱,不一定代表需要更用力地工作,有的时候,只是需要比竞争者更懂得让客户了解你的价值。王川在文章中对于 Dan Lok 的经验总结,大抵也是相同的意思
- 你必须自己花过很多钱购买某个服务/商品,才能理解那些客户的心理,才能更好地对他们销售
- 没有花过钱的人,会以己度人,推销自己认为重要的价值点
- 遇到潜在客户的问题和犹豫时,第一反应是降价来促销 (用自己的价值观来揣测) , 而不真正理解高端客户的痛点和兴奋点
- 只和真正有经济实力的客户合作,不和没有支付能力的人浪费时间
- 只和意愿强烈的客户合作,将大大减少自己的工作量
- 把自身大量有价值的信息通过社交媒体大规模传播出去。客户主动上门来找你,和你挨家挨户 cold call 找客户,是天壤之别
- 对于客户的问询质疑,最强大的回答是”I don’t know” (我不知道),让客户自己去解答自己的问题。主动去试图解释推销,往往会有反效果,让客户产生本能的抵触情绪
- 上述原则,即使在你很穷的时候,也要坚守。否则你很容易浪费大量时间在不匹配的客户上,无法赚钱,心态很不爽,很难真正摆脱困境
相关链接
【技术】RAG 的实现原理
在第一期的文章中介绍了艾逗笔实现的 AI 搜索引擎 ThinkAny 的文章,当中提到 RAG 技术,这篇内容就来详细介绍一下 RAG 的实现原理
RAG(Retrieval-Augmented Generation)检索增强生成,RAG 技术就像给 AI 配备了一个专门的参考书库,让 AI 在回答问题时能够查阅更多相关信息,从而提供更准确、更专业的答案
需要给大模型提供参考书库的原因
- 幻觉问题:LLM 大模型基于概率进行预测,有时会产生不准确或似是而非的答案,尤其在模型不擅长的领域更为严重
- 缺乏可解释性:LLM 模型像一个黑盒,用户难以了解模型使用了哪些数据进行训练,导致生成答案的追踪和理解变得困难
- 缺乏专业领域知识:LLM 的知识获取依赖于训练数据集的广度,对于企业内部数据、特定领域或高度专业化的知识,可能无法有效学习
- 数据安全性问题:企业不愿意承担数据泄露的风险,不愿意将私域数据上传到第三方平台进行训练
- 知识时效性不足:大模型的结构一旦固化,难以对最新发生的事件给出及时的回答
- 微调的局限性和成本:尽管微调可以一定程度上改善模型性能,但无法根本解决幻觉问题,且高频微调的成本过高
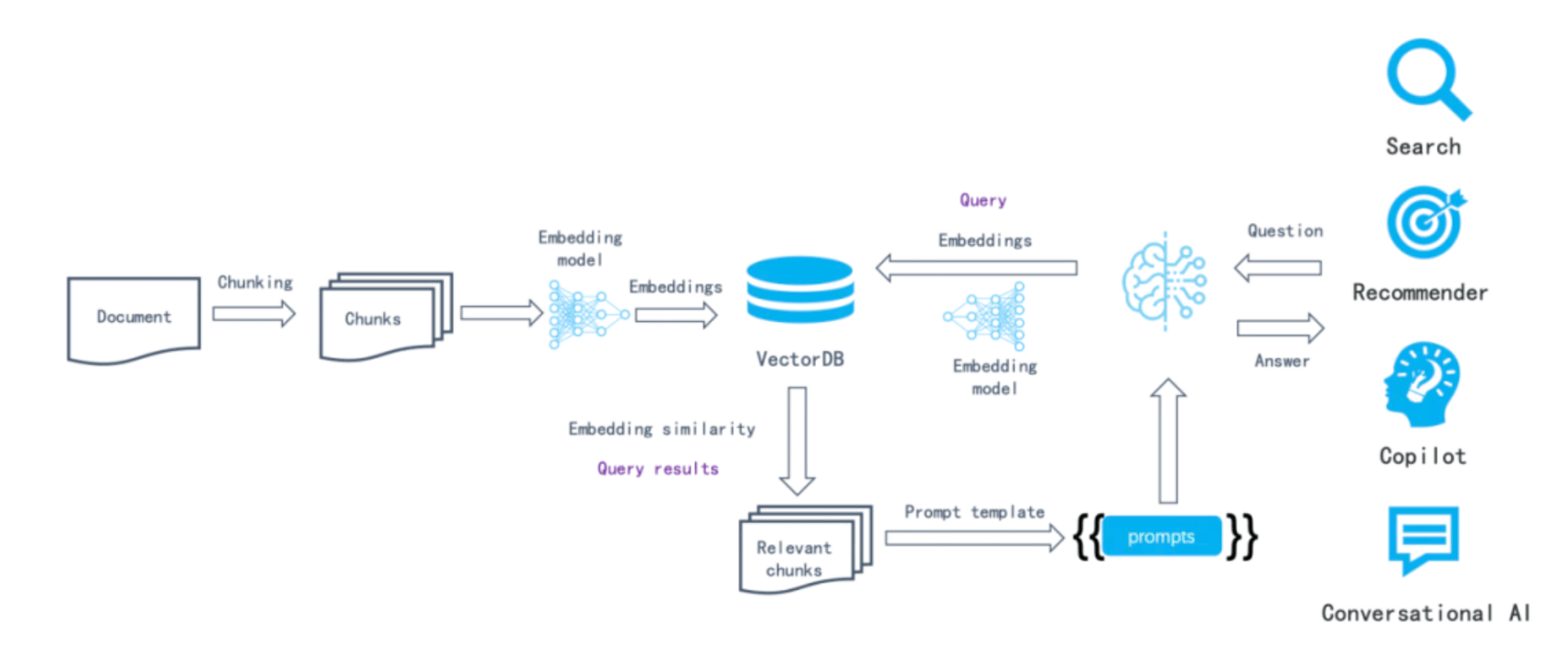
RAG 的 5 个实现步骤
- 文档分块:将长文档切分为小块,以提高检索效率
- 文本向量化:使用嵌入模型(Embedding)将文本转换为向量,通过计算向量之间的差异,来识别语意相似的句子
- 存储向量:将向量化的文本存入向量数据库,便于快速检索
- 查询检索:将用户问题向量化,并在数据库中检索最相关的内容
- 生成回答:结合用户问题和检索结果,由大模型生成最终答案
针对上面 5 个实现步骤,对于 RAG 的优化主要分为 4 个方面:知识分块与索引优化、用户 query 改写优化、数据召回优化和内容生成优化
对于知识分块与索引优化
- 第一阶段:按照固定字符拆分知识,并通过设置冗余字符来降低句子截断的问题,使一个完整的句子要么在上文,要么在下文
- 第二阶段:主要是解决索引混淆问题:核心关键词被湮没在大量的无效信息中
- 索引降噪:根据业务特点,去除索引数据中的无效成分,突出其核心知识
- 多级索引:创建两个索引,一个由文档摘要组成,另一个由文档块组成。首先通过摘要过滤掉相关文档,然后只在这个相关组内进行搜索
- HYDE(Hypothetical Document Embeddings):用 LLM 生成一个“假设”答案,将其和问题一起进行检索
- 第三阶段:主要是解决句子含义联系比较紧密的片段被切分成了两条数据的问题
- 训练专门的语义理解小模型:使用实际语义进行句子拆分,使拆分出来的知识片段语义更加完整
- 构建元数据:增加内容摘要、时间戳、用户可能提出的问题等附加信息来丰富知识库
- 建立知识图谱:利用知识图谱建立的索引,提取实体以及实体之间的关系
对于用户 query 的改写优化
- 第一阶段:采用 “查询重写” 方案,即直接利用 LLM 大模型重新表述问题,结合上下文,突出用户意图
- 第二阶段:使用 RAG-Fusion 解决需要组合多种知识才能找到答案的问题
- 对用户的原始 query 进行扩充:使用 LLM 模型对用户的初始查询,改写生成多个查询
- 对每个生成的查询进行基于向量的搜索,形成多路搜索召回
- 应用倒数排名融合算法,根据文档在多个查询中的相关性重新排列文档,生成最终输出
- 第三阶段:使用 Step-Back Prompting 解决原始查询太复杂或返回的信息太广泛的问题
- 即:选择生成一个抽象层次更高的“退后”问题,与原始问题一起用于检索,以增加返回结果的数量
- 比如:对于问题“勒布朗詹姆斯在2005年至2010年在哪些球队?
- 这个问题因为有时间范围的详细限制,比较难直接解决
- 可以提出一个后退问题“勒布朗詹姆斯的职业生涯是怎么样的?”从这个回答的召回结果中再检索上一个问题的答案
对于数据召回的优化
- 第一阶段:使用最简单的向量召回方式,找到在语义向量维度最近似的答案进行召回,只需要找到合适的 embedding 模型和向量数据库即可
- 第二阶段:解决当文本向量化模型训练不够好时,向量召回的准确率比较低的问题
- 分词召回:基于统计输入短语中的单词频率,频繁出现的单词得分较低,而稀有的词被视为关键词,得分会较高。可以结合稀疏和稠密搜索得出最终结果
- 多路召回:结果经过模型精排,最终筛选出优质结果
- 第三阶段:进一步提升召回准确度
- 图谱召回:如果在知识分块环节使用了知识图谱,直接用图谱召回,大幅提升召回准确度
- Agentic-rag:RAG 应用退化成一个 Agent 使用的知识工具,针对一个文档/知识库构建多种不同的 RAG 引擎
- 比如使用向量索引来回答事实性问题
- 使用摘要索引来回答总结性问题
- 使用知识图谱索引来回答需要更多关联性的问题等
对于内容生成的优化
- 第一阶段:只将上数据召回环节返回的 top 10 的知识筛选出来,提供给大模型生成答案即可
- 第二阶段:提升内容生成的准确性
- 文档合并去重:多路召回可能都会召回同一个结果,针对这部分数据要去重,否则对大模型输入的token数是一种浪费;其次,去重后的文档可以根据数据切分的血缘关系,做文档的合并
- 重排模型:通过对初始检索结果进行更深入的相关性评估和排序,确保最终展示给用户的结果更加符合其查询意图
- 第三阶段:进一步提升内容生成准确性
- Prompt 优化:RAG 中的 prompt 应明确指出回答仅基于搜索结果,不要添加任何其他信息
- Self-rag:self-rag 通过检索评分(令牌)和反思评分(令牌)来提高质量,主要分为三个步骤:检索、生成和批评
- 用检索评分来评估用户提问是否需要检索,如果需要检索,LLM 将调用外部检索模块查找相关文档
- LLM 分别为每个检索到的知识块生成答案,然后为每个答案生成反思评分来评估检索到的文档是否相关
- 将评分高的文档当作最终结果一并交给 LLM
相关链接
- 谈谈 Rag 的产生原因、基本原理与实施路径
- 实现垂类 AI 搜索引擎 SOP - 艾逗笔
- RAGFlow Reaches 10,000 Stars on GitHub: Time to Reflect on the Future of RAG | BestBlogs
【观点】不内卷的五条岔路
内卷这个词已经是互联网打工人的常态了,内卷简单来说就是无效地投入、没有发展的增长
社会学家项飙有一个观点:现代人的贫困,其实是意义贫困,无法看到自己所做事情的意义是什么。内卷本质上也是造成意义贫困的原因,在没有产生价值的工作中,反复内耗
解决内卷化的发展是一个漫长而缓慢的过程,推荐的这篇文章给出的 5 个方法,也只是这漫长探索中的一小部分
第一条:锚定工作的意义
- 在一份调研中,有 90% 的人感到职业倦怠,导致倦怠的主因是:会议太多、自主权太少、工作角色不明确、被赋予与工作无关的责任、以及有毒的工作环境
- 所以,工作不仅仅是谋生手段,更应与个人价值观相符,这份工作最好能帮助他人、或改善社会
- 以及,你需要热爱你的工作,如果我们的工作能够与我们的兴趣和热情相结合,那么我们就更容易找到工作的意义
- 查理·芒格对于找到有意义工作的建议:不要卖你不会买的东西,不要为不钦佩的人工作,与志同道合的人共事
第二条:唤醒内在驱动力
- 物质奖励是现代社会最常见驱动力来源,比如:老板答应我们加薪,我们的工作就格外卖力;用功渴望拿到好分数、考上更好的学校,我们就花更多时间读书;迟到要扣薪水,我们就乖乖准时上班
- 但是,物质奖励会令内在动机消失,令成绩下降,扼杀创造力,抑制善行,会鼓励敲诈、走捷径以及不道德的行为,还会让人上瘾,滋生短视思维
- 所以,找到与物质奖励相对的内在驱动力,找到自主性、创造力和个人满足感,才是解决内卷陷阱的方式
- Google 的“ 20% 时间”政策:员工可以将 20% 的工作时间用于自己感兴趣的项目
- 微软的“四天工作周”试验:在一个月中美洲至工作四天,结果显示员工的生产力提高了 40%
第三条:训练心流体验
- “心流”理论,描述了一种能够产生强烈幸福感的状态:我们在做某些事情时,那种全神贯注、投入忘我的状态——这种状态下,甚至感觉不到时间的存在,在这件事情完成之后我们会有一种充满能量并且非常满足的感受
- 心流产生需要三个基本条件:目标明确、即时反馈,技能-挑战相平衡,此外还需要你对手头任务充满热情或无比热爱,感觉通过这个任务,你的技能水平或总体成就可以得到提高
- 在现在的职场环境中,对于工作任务、目标不明确、缺少反馈的情况下,对于进入心流的建议是:避开嘈杂和可能被打断的环境,以保持注意力专注
第四条:适度钝感力
- 在渡边淳一的《钝感力》这本书中建议:人们应该学会接受生活中的不完美,不要过于在意别人的看法,不要过于追求成功,而应该专注于自己的内心和真实的感受
- 此外,钝感力还有助于我们遭遇失败时更为从容,同时保有反思的意愿和能力
第五条:拥抱黑天鹅
- 黑天鹅事件是指:不可预测但具有重大影响力的事件,是不确定性的体现
- 我们无法避免黑天鹅,所以更好的方式是:从不确定性中获益
- 塔勒布说,对随机性、不确定性和混沌也是一样:你要利用它们,而不是躲避它们。你要成为火,渴望得到风的吹拂
- 核心是建立“反脆弱性”,首要策略是多元化,无论是投资、业务还是技能,多元化都可以帮助我们抵御不确定性带来的风险
相关链接
工具推荐
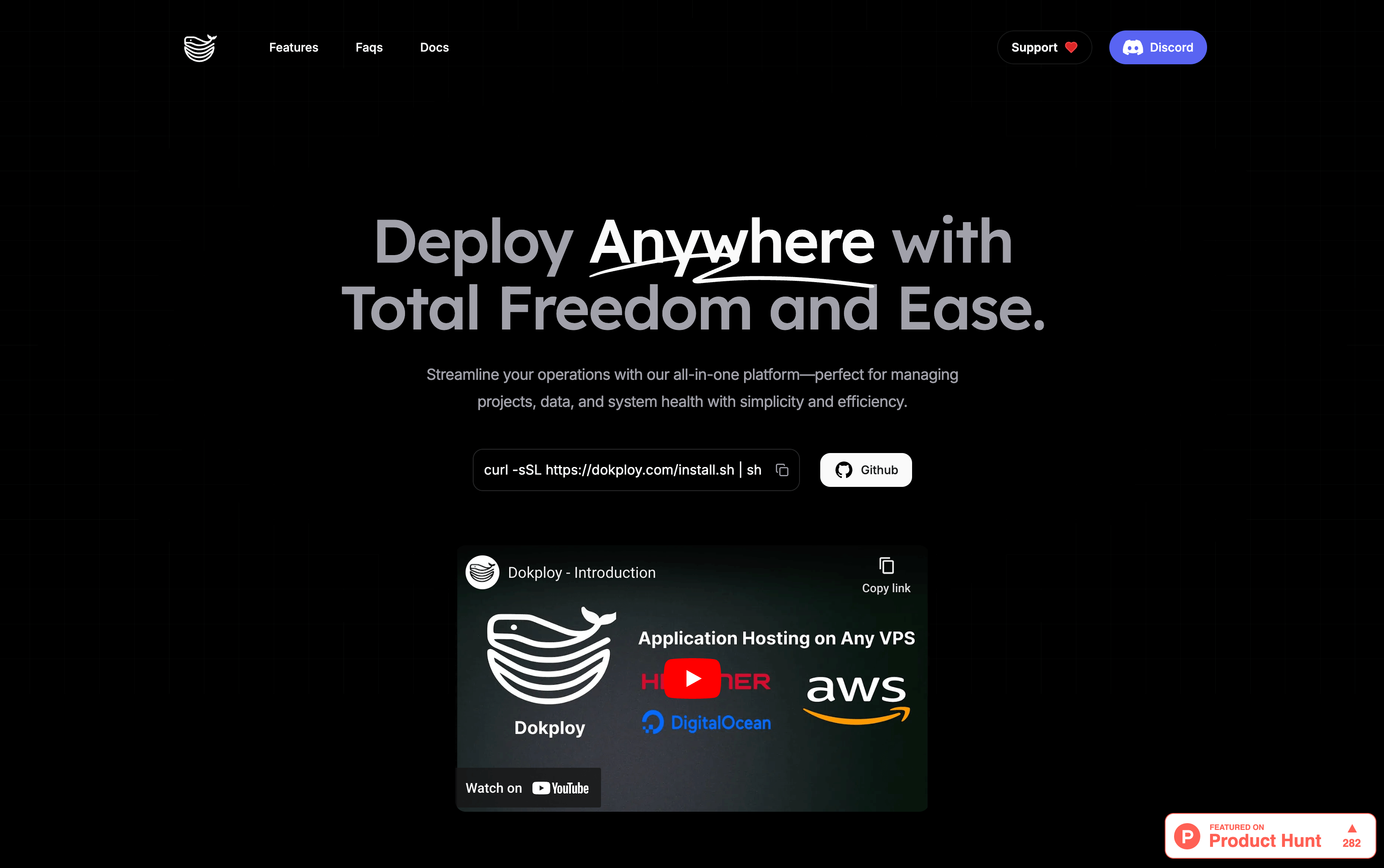
- Dokploy - Effortless Deployment Solutions:vercel 的开源替代版,作为独立开发者部署服务又多了一个新的选择
- wandb/openui: vercel 出品的 v0 开源替代版,通过文字描述生成代码,再结合 claude 3.5 sonnet 强大的代码生成能力,写代码变得非常简单
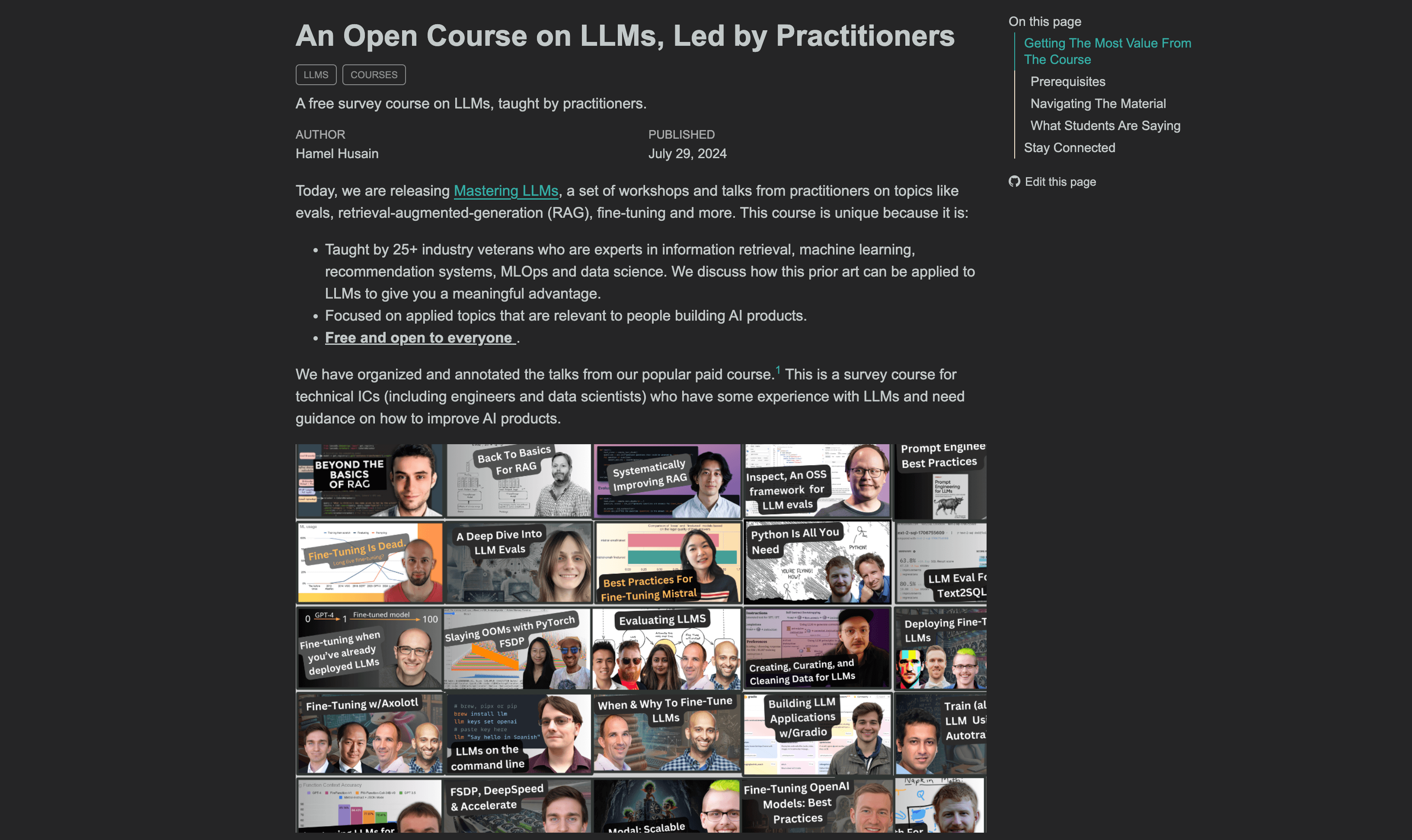
- Mastering LLMs:An Open Course on LLMs:一个由行业专家主讲的免费大型语言模型课程,课程内容涵盖评估、检索增强生成、微调等主题,适合小白入门
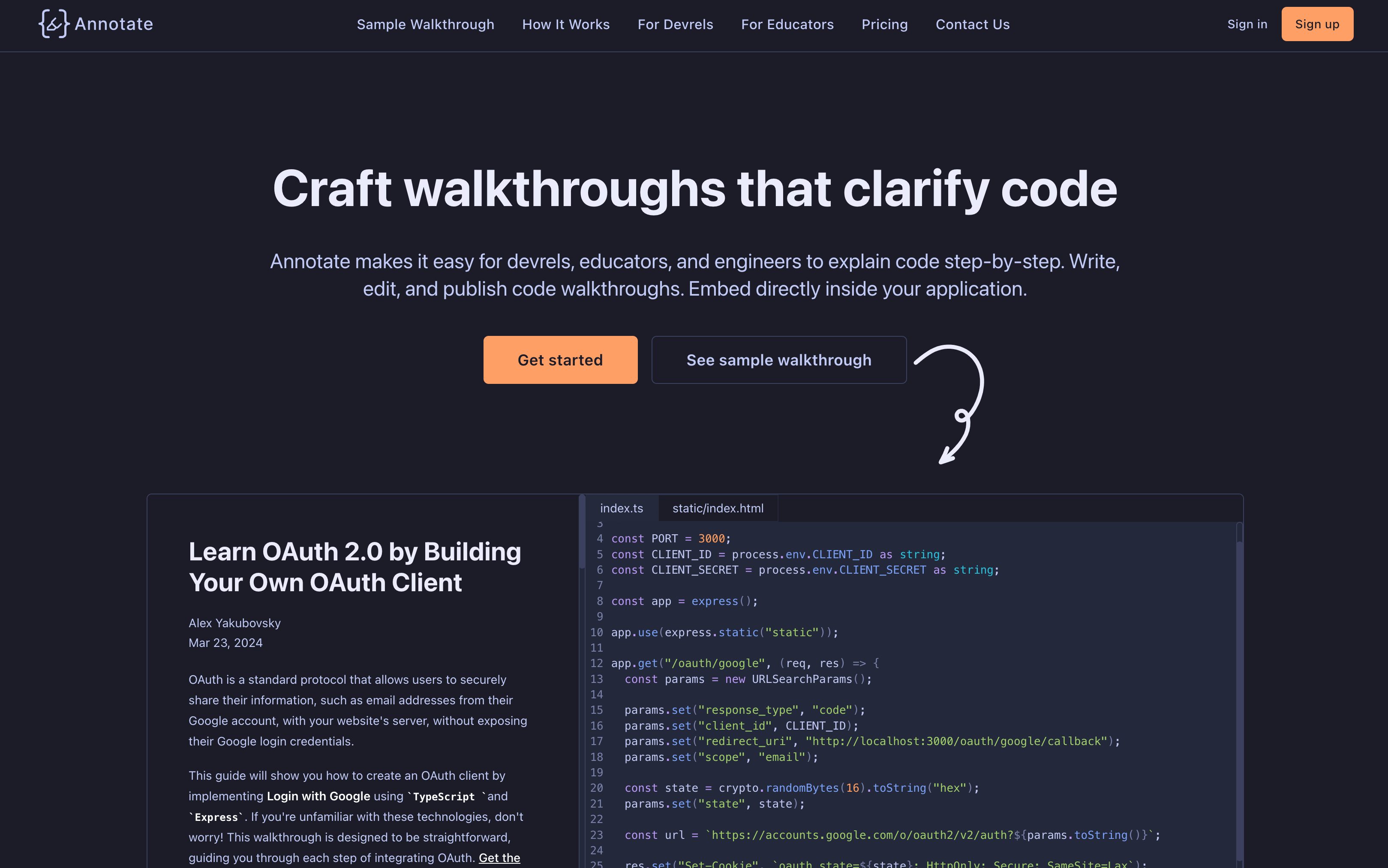
- Annotate:Craft walkthroughs that clarify code:逐步解释代码实现过程的工具,可交互式博客的一个新选择
- design-foundations:能够自动抓取网站字体、配色、icon 的工具,适合用来学习其他优秀的网站设计