Large Language Models (LLMs) hold immense potential, but developing reliable production-grade applications remains challenging. After building dozens of LLM systems, I’ve distilled the formula for success into 3+1 fundamental principles that any team can apply.
大型语言模型 (LLM) 具有巨大的潜力,但开发可靠的生产级应用程序仍然具有挑战性。在构建了数十个 LLM 系统后,我将成功的公式提炼为任何团队都可以应用的 3+1 基本原则。
“LLM-Native apps are 10% sophisticated model, and 90% experimenting data-driven engineering work.”
“LLM-Native 应用程序 10% 是复杂模型,90% 是实验数据驱动的工程工作。”
Building production-ready LLM applications requires careful engineering practices. When users cannot interact directly with the LLM, the prompt must be meticulously composed to cover all nuances, as iterative user feedback may be unavailable.
构建可投入生产的应用程序需要仔细的工程实践。当用户无法直接与 LLM 交互时,必须精心编写提示以涵盖所有细微差别,因为可能无法获得迭代的用户反馈。
Introducing the LLM Triangle Principles
LLM 三角原则
The LLM Triangle Principles encapsulate the essential guidelines for building effective LLM-native apps. They provide a solid conceptual framework, guide developers in constructing robust and reliable LLM-native applications, and offer direction and support.
LLM 三角原则概括了构建有效的 LLM 原生应用程序的基本准则。它们提供了坚实的概念框架,指导开发人员构建强大且可靠的 LLM 本地应用程序,并提供指导和支持。

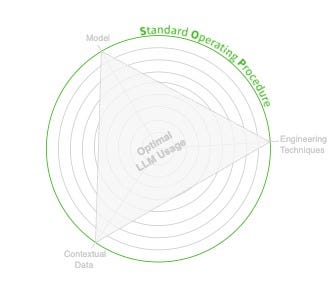
An optimal LLM Usage is achieved by optimizing the three prominent principles through the lens of the SOP. (Image by author)
通过 SOP 的视角优化三个主要原则来实现最佳 LLM 使用。(作者提供的图片)
The Key Apices
关键顶点
The LLM Triangle Principles introduces four programming principles to help you design and build LLM-Native apps.
LLM 三角原则引入了四个编程原则,帮助您设计和构建 LLM 原生应用程序。
The first principle is the Standard Operating Procedure (SOP). The SOP guides the three apices of our triangle: Model, Engineering Techniques, and Contextual Data.
第一个原则是标准操作程序(SOP)。SOP 指导我们三角形的三个顶点:模型、工程技术和上下文数据。
Optimizing the three apices principles through the lens of the SOP is the key to ensuring a high-performing LLM-native app.
通过 SOP 的视角优化三个顶点原则是确保高性能 LLM 原生应用程序的关键。
1. Standard Operating Procedure (SOP)
1. 标准操作程序(SOP)
Standard Operating Procedure (SOP) is a well-known terminology in the industrial world. It’s a set of step-by-step instructions compiled by large organizations to help their workers carry out routine operations while maintaining high-quality and similar results each time. This practically turns inexperienced or low-skilled workers into experts by writing detailed instructions.
标准操作程序 (SOP) 是工业界的一个著名术语。它是一组由大型组织编写的逐步说明,帮助其员工在每次执行例行操作时保持高质量和类似的结果。这实际上通过编写详细的说明将没有经验或技能较低的工人变成专家。
The LLM Triangle Principles borrow the SOP paradigm and encourage you to consider the model as an inexperienced/unskilled worker. We can ensure higher-quality results by “teaching” the model how an expert would perform this task.
LLM 三角原则借用 SOP 范式,鼓励您将模型视为没有经验/技能的工人。通过“教”模型如何像专家一样执行此任务,我们可以确保更高质量的结果。
The SOP guiding principle. (image by author)
SOP 指导原则
“Without an SOP, even the most powerful LLM will fail to deliver consistently high-quality results.”
“没有 SOP,即使是最强大的 LLM 也无法持续提供高质量的结果。”
When thinking about the SOP guiding principle, we should identify what techniques will help us implement the SOP most effectively.
在考虑 SOP 指导原则时,我们应该确定哪些技术将帮助我们最有效地实施 SOP。
1.1. Cognitive modeling
1.1. 认知建模
To create an SOP, we need to take our best-performing workers (domain experts), model how they think and work to achieve the same results, and write down everything they do.
要创建 SOP,我们需要将表现最好的工人(领域专家)作为模型,了解他们如何思考和工作以获得相同的结果,并记录他们所做的一切。
After editing and formalizing it, we’ll have detailed instructions to help every inexperienced or low-skilled worker succeed and yield excellent work.
在编辑和正式化之后,我们将拥有详细的说明,帮助每个没有经验或技能较低的工人成功并产生出色的工作。
Like humans, it’s essential to reduce the cognitive load of the task by simplifying or splitting it. Following a simple step-by-step instruction is more straightforward than a lengthy, complex procedure.
像人类一样,通过简化或拆分任务来减少认知负荷是至关重要的。遵循简单的逐步说明比冗长复杂的程序更容易。
During this process, we identify the hidden implicit cognition “jumps” — the small, unconscious steps experts take that significantly impact the outcome. These subtle, unconscious, often unspoken assumptions or decisions can substantially affect the final result.
在此过程中,我们识别出隐藏的隐性认知“跳跃”——专家们采取的对结果有显著影响的小的无意识步骤。这些微妙的、无意识的、通常未说出的假设或决定可能会对最终结果产生重大影响。

An example of an “implicit cognition jump.” (Image by author)
“隐性认知跳跃”的一个例子。
For example, let’s say we want to model an SQL analyst. We’ll start by interviewing them and ask them a few questions, such as:
- What do you do when you are asked to analyze a business problem?
- How do you make sure your solution meets the request?
- reflecting the process as we understand to the interviewee
- Does this accurately capture your process? getting corrections
- Etc.
例如,假设我们想要建模一个 SQL 分析师。我们将从采访他们开始,问他们一些问题,例如:
- 当被要求分析业务问题时,你会做什么?
- 你如何确保你的解决方案符合要求?
- 反映我们对受访者的理解过程
- 这是否准确地捕捉了你的过程?获取修正
- 等等。
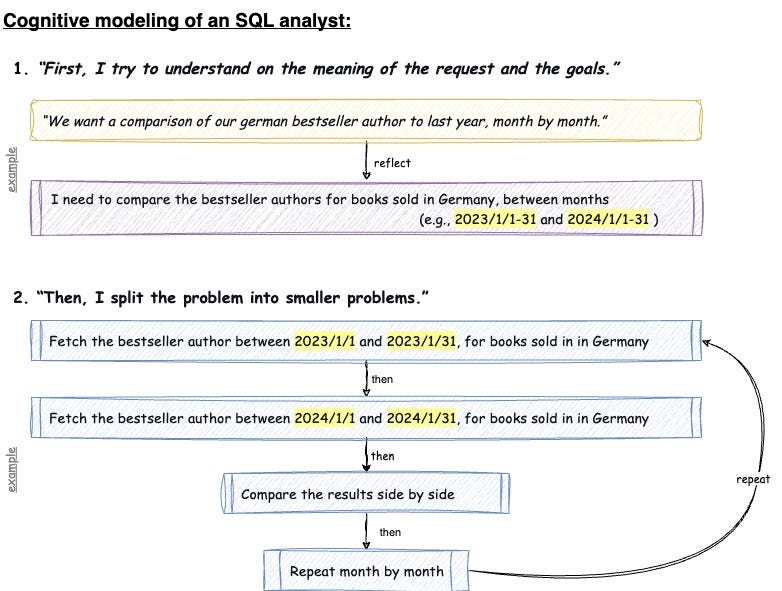
An example of the cognitive process that the analyst does and how to model it. (Image by author)
分析师的认知过程示例以及如何建模它。
The implicit cognition process takes many shapes and forms; a typical example is a “domain-specific definition.” For example, “bestseller” might be a prominent term for our domain expert, but not for everyone else.
隐性认知过程有多种形式;一个典型的例子是“领域特定定义”。例如,“畅销书”可能是我们领域专家的一个重要术语,但对其他人来说却不是。

Expanding the implicit cognition process in our SQL analyst example. (Image by author)
在我们的 SQL 分析师示例中扩展隐性认知过程。
Eventually, we’ll have a full SOP “recipe” that allows us to emulate our top-performing analyst.
最终,我们将拥有一个完整的 SOP“配方”,使我们能够模拟表现最好的分析师。
When mapping out these complex processes, it can be helpful to visualize them as a graph. This is especially helpful when the process is nuanced and involves many steps, conditions, and splits.
在绘制这些复杂过程时,将它们可视化为图表可能会有所帮助。这在过程复杂且涉及许多步骤、条件和分支时尤其有用。
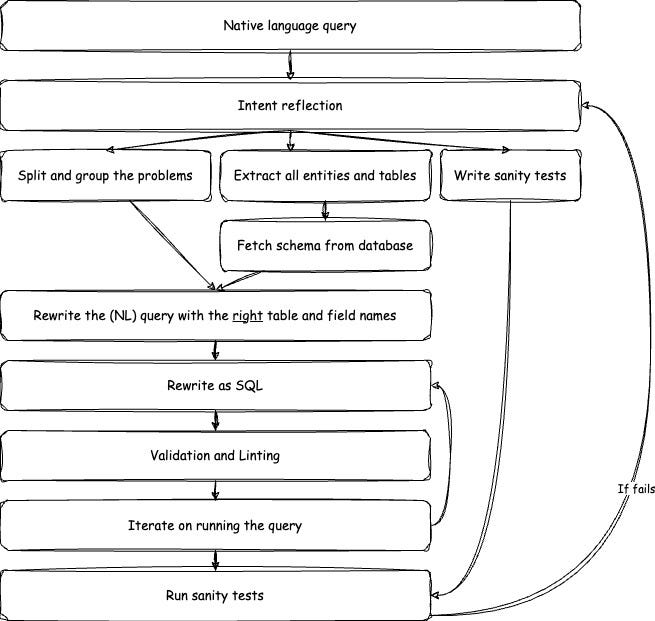
The “SQL Analyst SOP” includes all the required technical steps, visualized as a graph. (Image by author)
“SQL 分析师 SOP”包括所有必要的技术步骤,以图表形式可视化。
Our final solution should mimic the steps defined in the SOP. In this stage, try to ignore the implementation—later, you can implement it across one or many steps/chains throughout our solution.
我们的最终解决方案应模仿 SOP 中定义的步骤。在此阶段,尽量忽略实现——稍后,您可以在我们的解决方案中跨一个或多个步骤/链实现它。
Unlike the rest of the principles, the cognitive modeling (SOP writing) is the only standalone process. It’s highly recommended that you model your process before writing code. That being said, while implementing it, you might go back and change it based on new insights or understandings you gained.
与其他原则不同,认知建模(SOP 编写)是唯一独立的过程。强烈建议您在编写代码之前对您的过程进行建模。也就是说,在实施过程中,您可能会根据获得的新见解或理解进行更改。
Now that we understand the importance of creating a well-defined SOP, that guides our business understanding of the problem, let’s explore how we can effectively implement it using various engineering techniques.
现在我们了解了创建定义明确的 SOP 的重要性,它指导我们对问题的业务理解,让我们探讨如何使用各种工程技术有效地实施它。
2. Engineering Techniques
2. 工程技术
Engineering Techniques help you practically implement your SOP and get the most out of the model. When thinking about the Engineering Techniques principle, we should consider what tools(techniques) in our toolbox can help us implement and shape our SOP and assist the model in communicating well with us.
工程技术帮助您实际实施 SOP 并充分利用模型。在考虑工程技术原则时,我们应该考虑工具箱中的哪些工具(技术)可以帮助我们实施和塑造 SOP 并帮助模型与我们良好沟通。
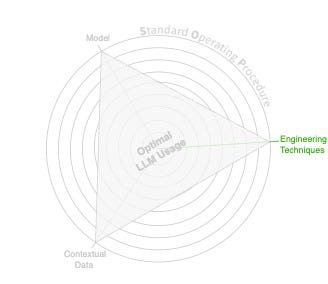
The Engineering Techniques principle. (Image by author)
工程技术原则。
Some engineering techniques are only implemented in the prompt layer, while many require a software layer to be effective, and some combine both layers.
一些工程技术仅在提示层实现,而许多需要软件层才能有效,有些则结合了两个层。
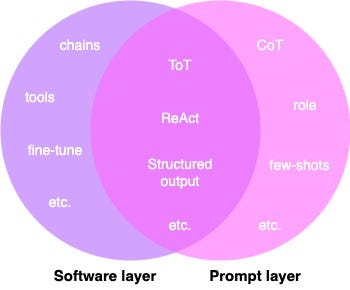
Engineering Techniques Layers. (Image by author)
工程技术层。
While many small nuances and techniques are discovered daily, I’ll cover two primary techniques: workflow/chains and agents.
虽然每天都会发现许多小的细微差别和技术,但我将介绍两种主要技术:工作流/链和代理。
2.1. LLM-Native architectures (aka flow engineering or chains)
2.1. LLM 原生架构(又名流工程或链)
The LLM-Native Architecture describes the agentic flow your app is going through to yield the task’s result.
LLM 原生架构描述了您的应用程序为完成任务而经历的代理流。
Each step in our flow is a standalone process that must occur to achieve our task. Some steps will be performed simply by deterministic code; for some, we will use an LLM (agent).
我们流中的每一步都是一个独立的过程,必须发生才能完成任务。有些步骤将由确定性代码简单执行;对于某些步骤,我们将使用 LLM(代理)。
To do that, we can reflect on the Standard Operating Procedure (SOP) we drew and think:
- Which SOP steps should we glue together to the same agent? And what steps should we split as different agents?
- What SOP steps should be executed in a standalone manner (but they might be fed with information from previous steps)?
- What SOP steps can we perform in a deterministic code?
- Etc.
为此,我们可以反思我们绘制的标准操作程序(SOP)并思考:
- 哪些 SOP 步骤应该粘合在同一个代理中?哪些步骤应该拆分为不同的代理?
- 哪些 SOP 步骤应独立执行(但它们可能会从前面的步骤中获取信息)?
- 哪些 SOP 步骤可以通过确定性代码执行?
- 等等。
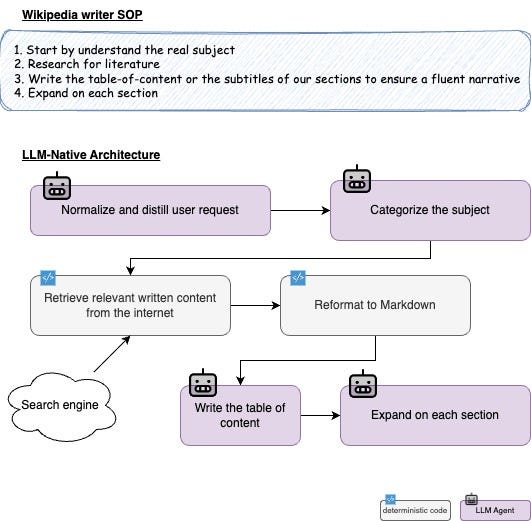
An LLM-Native Architecture example for “Wikipedia writer” based on a given SOP. (Image by author)
基于给定 SOP 的“维基百科作者” LLM 原生架构示例。
Before navigating to the next step in our architecture/graph, we should define its key properties:
- Inputs and outputs — What is the signature of this step? What is required before we can take an action? (this can also serve as an output format for an agent)
- **Quality assurances—**What makes the response “good enough”? Are there cases that require human intervention in the loop? What kinds of assertions can we configure?
- Autonomous level — How much control do we need over the result’s quality? What range of use cases can this stage handle? In other words, how much can we trust the model to work independently at this point?
- Triggers — What is the next step? What defines the next step?
- Non-functional — What’s the required latency? Do we need special business monitoring here?
- Failover control — What kind of failures(systematic and agentic) can occur? What are our fallbacks?
- State management — Do we need a special state management mechanism? How do we retrieve/save states (define the indexing key)? Do we need persistence storage? What are the different usages of this state(e.g., cache, logging, etc.)?
- Etc.
在导航到我们架构/图中的下一步之前,我们应该定义其关键属性:
- 输入和输出——此步骤的签名是什么?在我们采取行动之前需要什么?(这也可以作为代理的输出格式)
- 质量保证——什么使响应“足够好”?是否有需要人类介入的情况?我们可以配置哪些断言?
- 自主水平——我们对结果质量需要多少控制?此阶段可以处理哪些范围的用例?换句话说,我们在这一点上可以多大程度上信任模型独立工作?
- 触发器——下一步是什么?是什么定义了下一步?
- 非功能性——所需的延迟是多少?我们这里需要特殊的业务监控吗?
- 故障转移控制——可能发生什么样的故障(系统性和代理性)?我们的回退是什么?
- 状态管理——我们需要特殊的状态管理机制吗?我们如何检索/保存状态(定义索引键)?我们需要持久存储吗?这种状态的不同用途是什么(例如缓存、日志记录等)?
- 等等。
2.2. What are agents?
2.2. 什么是代理?
An LLM agent is a standalone component of an LLM-Native architecture that involves calling an LLM.
LLM 代理是 LLM 原生架构的独立组件,涉及调用 LLM。
It’s an instance of LLM usage with the prompt containing the context. Not all agents are equal — Some will use “tools,” some won’t; some might be used “just once” in the flow, while others can be called recursively or multiple times, carrying the previous input and outputs.
它是包含上下文的提示的 LLM 使用实例。并非所有代理都是平等的——有些将使用“工具”,有些则不会;有些可能在流中只使用一次,而其他可能会递归或多次调用,携带先前的输入和输出。
2.2.1. Agents with tools
2.2.1. 具有工具的代理
Some LLM agents can use “tools” — predefined functions for tasks like calculations or web searches. The agent outputs instructions specifying the tool and input, which the application executes, returning the result to the agent.
一些 LLM 代理可以使用“工具”——用于计算或网络搜索等任务的预定义函数。代理输出指定工具和输入的指令,应用程序执行这些指令,并将结果返回给代理。
To understand the concept, let’s look at a simple prompt implementation for tool calling. This can work even with models not natively trained to call tools:
要理解这个概念,让我们看看一个简单的工具调用提示实现。这甚至可以与未经过本地训练以调用工具的模型一起工作:
You are an assistant with access to these tools:
- calculate(expression: str) → str - calculate a mathematical expression
- search(query: str) → str - search for an item in the inventory
你是一个拥有以下工具的助手:
- calculate(expression: str) → str - 计算数学表达式
- search(query: str) → str - 在库存中搜索项目
Given an input, Respond with a YAML with keys: func(str) and arguments(map) or message(str).Given input
给定输入,使用键 func(str) 和 arguments(map) 或 message(str) 响应 YAML。给定输入
It’s important to distinguish between agents with tools (hence autonomous agents) and agents whose output can lead to performing an action.
重要的是要区分具有工具的代理(因此是自主代理)和输出可以导致执行操作的代理。
“Autonomous agents are agents that have the ability to generate a way to accomplish the task.”
“自主代理是具有生成完成任务的方法的能力的代理。”
Autonomous agents are given the right to decide if they should act and with what action. In contrast, a (nonautonomous) agent simply “processes” our request(e.g., classification), and based on this process, our deterministic code performs an action, and the model has zero control over that.
自主代理被赋予决定是否应该采取行动以及采取什么行动的权利。相比之下,(非自主)代理只是“处理”我们的请求(例如分类),并基于此过程,我们的确定性代码执行操作,模型对此没有任何控制。
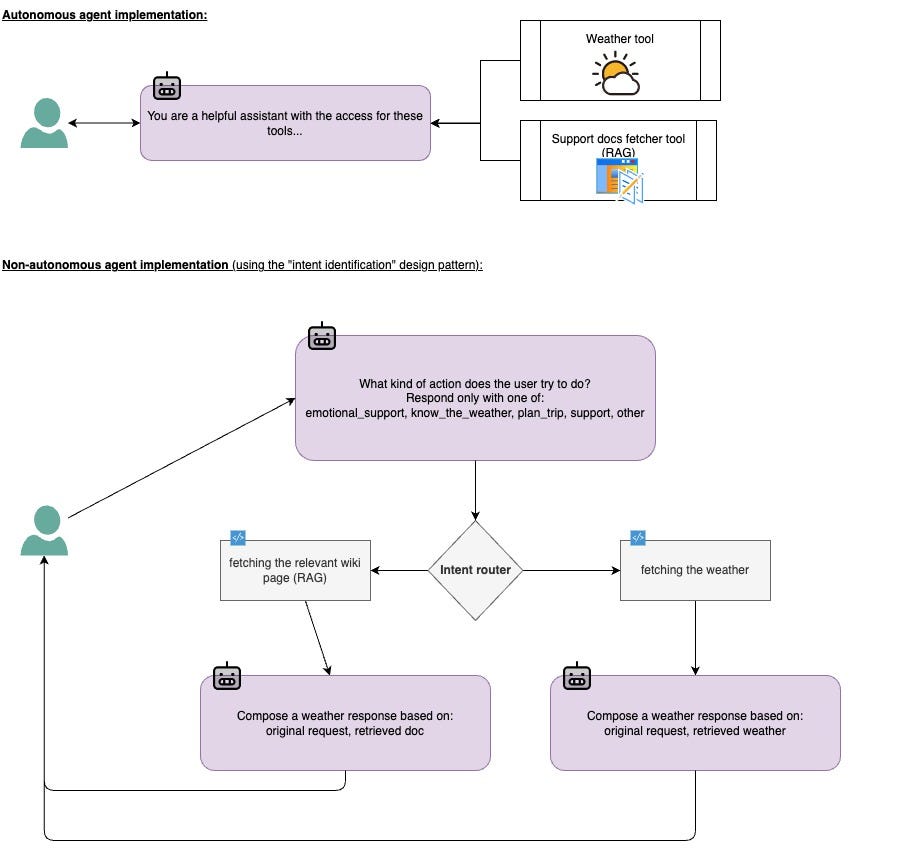
An autonomous agent VS agent that triggers an action. (Image by author)
自主代理与触发操作的代理。
As we increase the agent’s autonomy in planning and executing tasks, we enhance its decision-making capabilities but potentially reduce control over output quality. Although this might look like a magical solution to make it more “smart” or “advanced,” it comes with the cost of losing control over the quality.
随着我们提高智能体在规划和执行任务方面的自主性,我们增强了它的决策能力,但可能会减少对输出质量的控制。虽然这看起来像是一个让它更“智能”或“先进”的神奇解决方案,但它的代价是失去对质量的控制。

The tradeoffs of an autonomous agent. (Image by author)
自主代理的权衡。
Beware the allure of fully autonomous agents. While their architecture might look appealing and simpler, using it for everything (or as the initial PoC) might be very deceiving from the “real production” cases. Autonomous agents are hard to debug and unpredictable(response with unstable quality), which makes them unusable for production.
要小心完全自主代理的诱惑。虽然它们的架构可能看起来很吸引人且更简单,但将其用于所有事情(或作为初始 PoC)可能会在“实际生产”案例中非常具有欺骗性。自主代理难以调试且不可预测(响应质量不稳定),这使它们无法用于生产。
Currently, agents (without implicit guidance) are not very good at planning complex processes and usually skip essential steps. For example, in our “Wikipedia writer” use-case, they’ll just start writing and skip the systematic process. This makes agents (and autonomous agents especially) only as good as the model, or more accurately — only as good as the data they were trained on relative to your task.
目前,代理(没有隐性指导)在规划复杂过程方面表现不佳,通常会跳过重要步骤。例如,在我们的“维基百科作者”用例中,他们会直接开始写作并跳过系统过程。这使得代理(尤其是自主代理)只能与模型一样好,或者更准确地说——只能与相对于您的任务训练的数据一样好。
Instead of giving the agent (or a swarm of agents) the liberty to do everything end-to-end, try to hedge their task to a specific region of your flow/SOP that requires this kind of agility or creativity. This can yield higher-quality results because you can enjoy both worlds.
与其让代理(或一群代理)自由地完成所有事情,不如将其任务限制在需要这种灵活性或创造力的流/SOP 的特定区域。这可以产生更高质量的结果,因为您可以享受两全其美的好处。
An excellent example is AlphaCodium: By combining a structured flow with different agents (including a novel agent that iteratively writes and tests code), they increased GPT-4 accuracy (pass@5) on CodeContests from 19% to 44%.
一个很好的例子是 AlphaCodium:通过将结构化流程与不同的代理(包括一个迭代编写和测试代码的新代理)结合起来,他们将 GPT-4 在 CodeContests 上的准确性(pass@5)从 19% 提高到 44%。
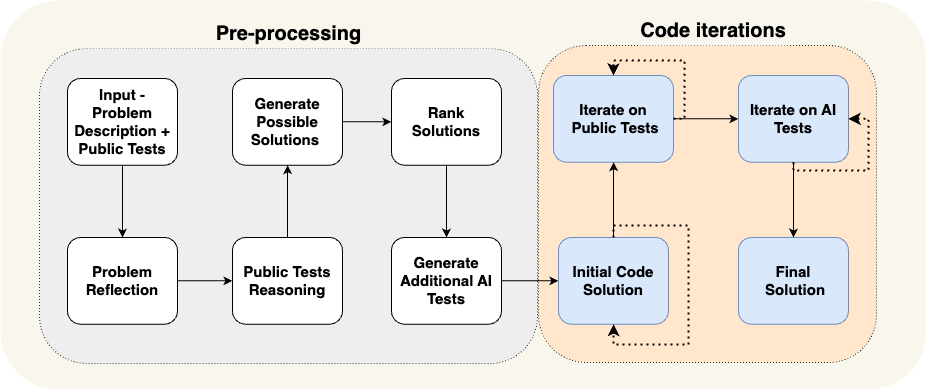
AlphaCodium’s LLM Architecture. (Image by the curtesy Codium.ai)
AlphaCodium 的 LLM 架构。
While engineering techniques lay the groundwork for implementing our SOP and optimizing LLM-native applications, we must also carefully consider another critical component of the LLM Triangle: the model itself.
虽然工程技术为实施我们的 SOP 和优化 LLM 原生应用程序奠定了基础,但我们还必须仔细考虑 LLM 三角的另一个关键组成部分:模型本身。
3. Model
3. 模型
The model we choose is a critical component of our project’s success—a large one (such as GPT-4 or Claude Opus) might yield better results but be quite costly at scale, while a smaller model might be less “smart” but help with the budget. When thinking about the Model principle, we should aim to identify our constraints and goals and what kind of model can help us fulfill them.
我们选择的模型是项目成功的关键组成部分——一个大型模型(如 GPT-4 或 Claude Opus)可能会产生更好的结果,但在规模上成本相当高,而一个较小的模型可能不那么“聪明”,但有助于预算。在考虑模型原则时,我们应该努力确定我们的约束和目标,以及哪种模型可以帮助我们实现这些目标。
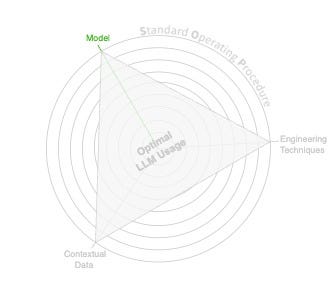
The Model principle. (Image by author)
模型原则。
“Not all LLMs are created equal. Match the model to the mission.”
“并非所有 LLM 都是平等的。将模型与任务匹配。”
The truth is that we don’t always need the largest model; it depends on the task. To find the right match, we must have an experimental process and try multiple variations of our solution.
事实是,我们并不总是需要最大的模型;这取决于任务。要找到合适的匹配,我们必须有一个实验过程并尝试我们的解决方案的多种变体。
It helps to look at our “inexperienced worker” analogy — a very “smart” worker with many academic credentials probably will succeed in some tasks easily. Still, they might be overqualified for the job, and hiring a “cheaper” candidate will be much more cost-effective.
有助于查看我们的“没有经验的工人”类比——一个拥有许多学术资质的非常“聪明”的工人可能会轻松完成某些任务。但他们可能过于胜任这项工作,雇用一个“更便宜”的候选人将更具成本效益。
When considering a model, we should define and compare solutions based on the tradeoffs we are willing to take:
- Task Complexity — Simpler tasks (such as summarization) are easier to complete with smaller models, while reasoning usually requires larger models.
- Inference infrastructure — Should it run on the cloud or edge devices? The model size might impact a small phone, but it can be tolerated for cloud-serving.
- Pricing — What price can we tolerate? Is it cost-effective considering the business impact and predicated usage?
- Latency — As the model grows larger, the latency grows as well.
- Labeled data — Do we have data we can use immediately to enrich the model with examples or relevant information that is not trained upon?
在考虑模型时,我们应该根据我们愿意接受的权衡来定义和比较解决方案:
- 任务复杂性——较简单的任务(如摘要)更容易用较小的模型完成,而推理通常需要较大的模型。
- 推理基础设施——它应该在云端还是边缘设备上运行?模型大小可能会影响小型手机,但可以容忍云服务。
- 定价——我们能容忍什么价格?考虑到业务影响和预测的使用情况,它是否具有成本效益?
- 延迟——随着模型变大,延迟也会增加。
- 标记数据——我们是否有数据可以立即用来丰富模型,提供示例或相关信息,而这些信息尚未被训练?
In many cases, until you have the “in-house expertise,” it helps to pay a little extra for an experienced worker — the same applies to LLMs.
在许多情况下,直到您拥有“内部专业知识”之前,支付额外费用以获得经验丰富的工人是有帮助的——LLM 也是如此。
If you don’t have labeled data, start with a stronger (larger) model, collect data, and then utilize it to empower a model using a few-shot or fine-tuning.
如果您没有标记数据,请从一个更强大的(更大的)模型开始,收集数据,然后利用它通过少量示例学习或微调来增强模型。
3.1. Fine-tuning a model
There are a few aspects that you must consider before resorting to fine-tune a model:
- Privacy — Your data might include pieces of private information that must be kept from the model. You must anonymize your data to avoid legal liabilities if your data contains private information.
- Laws, Compliance, and Data Rights — Some legal questions can be raised when training a model. For example, the OpenAI terms-of-use policy prevents you from training a model without OpenAI using generated responses. Another typical example is complying with the GDPR’s laws, which require a “right for revocation,” where a user can require the company to remove information from the system. This raises legal questions about whether the model should be retrained or not.
- Updating latency — The latency or data cutoff is much higher when training a model. Unlike embedding the new information via the context (see “4. Contextual Data” section below), which provides immediate latency, training the model is a long process that takes time. Due to that, models are retrained less often.
- Development and operation — Implementing a reproducible, scalable, and monitored fine-tuning pipeline is essential while continuously evaluating the results’ performance. This complex process requires constant maintenance.
- Cost — Retraining is considered expensive due to its complexity and the highly intensive resources(GPUs) required per training.
在决定微调模型之前,您必须考虑几个方面:
- 隐私——您的数据可能包含必须从模型中保留的私人信息。如果您的数据包含私人信息,您必须匿名化数据以避免法律责任。
- 法律、合规性和数据权利——在训练模型时可能会出现一些法律问题。例如,OpenAI 的使用条款政策禁止您在没有 OpenAI 的情况下使用生成的响应来训练模型。另一个典型的例子是遵守 GDPR 法律,这要求“撤销权”,用户可以要求公司从系统中删除信息。这引发了关于是否应该重新训练模型的法律问题。
- 更新延迟——训练模型时的延迟或数据截止时间要高得多。与通过上下文嵌入新信息(见下文“4. 上下文数据”部分)提供即时延迟不同,训练模型是一个需要时间的漫长过程。因此,模型的重新训练频率较低。
- 开发和运营——实施可重复、可扩展和受监控的微调管道至关重要,同时不断评估结果的性能。这个复杂的过程需要持续维护。
- 成本——由于其复杂性和每次训练所需的高强度资源(GPU),重新训练被认为是昂贵的。
The ability of LLMs to act as in-context learners and the fact that the newer models support a much larger context window simplify our implementation dramatically and can provide excellent results even without fine-tuning. Due to the complexity of fine-tuning, using it as a last resort or skipping it entirely is recommended.
LLM 作为上下文学习者的能力以及新模型支持更大上下文窗口的事实极大地简化了我们的实现,并且即使没有微调也能提供出色的结果。由于微调的复杂性,建议将其作为最后的手段或完全跳过。
Conversely, fine-tuning models for specific tasks (e.g., structured JSON output) or domain-specific language can be highly efficient. A small, task-specific model can be highly effective and much cheaper in inference than large LLMs. Choose your solution wisely, and assess all the relevant considerations before escalating to LLM training.
相反,针对特定任务(例如结构化 JSON 输出)或领域特定语言微调模型可能非常有效。一个小型、特定任务的模型可以非常有效,并且在推理方面比大型 LLM 便宜得多。明智地选择您的解决方案,并在升级到 LLM 训练之前评估所有相关考虑因素。
“Even the most powerful model requires relevant and well-structured contextual data to shine.”
“即使是最强大的模型也需要相关且结构良好的上下文数据才能发光。”
4. Contextual Data
4. 上下文数据
LLMs are in-context learners. That means that by providing task-specific information, the LLM agent can help us to perform it without special training or fine-tuning. This enables us to “teach” new knowledge or skills easily. When thinking about the Contextual Data principle, we should aim to organize and model the available data and how to compose it within our prompt.
LLM 是上下文学习者。 这意味着通过提供特定任务的信息,LLM 代理可以帮助我们执行任务,而无需特殊训练或微调。这使我们能够轻松地“教授”新知识或技能。在考虑上下文数据原则时,我们应该努力组织和建模可用数据以及如何在提示中构建它。

The Contextual Data principle. (Image by author)
上下文数据原则。
To compose our context, we include the relevant (contextual) information within the prompt we send to the LLM. There are two kinds of contexts we can use:
- Embedded contexts — embedded information pieces provided as part of the prompt.(嵌入上下文——作为提示的一部分提供的嵌入信息片段。)
You are the helpful assistant of `<name>`, a `<role>` at `<company>`
- Attachment contexts — A list of information pieces glues by the beginning/end of the prompt(附件上下文——通过提示的开头/结尾粘合的信息片段列表)
Summarize the provided emails while keeping a friendly tone.
---
`<email_0>`
`<email_1>`
Contexts are usually implemented using a “prompt template” (such as jinja2 or mustache or simply native formatting literal strings); this way, we can compose them elegantly while keeping the essence of our prompt:
上下文通常使用“提示模板”(例如 jinja2 或 mustache 或简单的本地格式化字符串)实现;这样,我们可以优雅地构建它们,同时保持提示的本质:
# Embedded context with an attachment context
prompt = f"""
You are the helpful assistant of {name}. {name} is a {role} at {company}.
Help me write a {tone} response to the attached email.
Always sign your email with:
{signature}
---
{email}
"""
4.1. Few-shot learning
4.1. 少量示例学习
Few-shot learning is a powerful way to “teach” LLMs by example without requiring extensive fine-tuning. Providing a few representative examples in the prompt can guide the model in understanding the desired format, style, or task.
少量示例学习是一种强大的方式,通过示例“教授” LLM,而无需进行广泛的微调。在提示中提供一些代表性示例可以指导模型理解所需的格式、风格或任务。
For instance, if we want the LLM to generate email responses, we could include a few examples of well-written responses in the prompt. This helps the model learn the preferred structure and tone.
例如,如果我们希望 LLM 生成电子邮件回复,我们可以在提示中包含一些写得很好的回复示例。这有助于模型学习首选的结构和语气。
We can use diverse examples to help the model catch different corner cases or nuances and learn from them. Therefore, it’s essential to include a variety of examples that cover a range of scenarios your application might encounter.
我们可以使用多样化的示例来帮助模型捕捉不同的边缘情况或细微差别并从中学习。因此,包含涵盖您的应用程序可能遇到的各种场景的多种示例至关重要。
As your application grows, you may consider implementing “Dynamic few-shot,” which involves programmatically selecting the most relevant examples for each input. While it increases your implementation complexity, it ensures the model receives the most appropriate guidance for each case, significantly improving performance across a wide range of tasks without costly fine-tuning.
随着您的应用程序的增长,您可能会考虑实现“动态少量示例”,这涉及程序化地为每个输入选择最相关的示例。虽然这增加了您的实现复杂性,但它确保模型在每种情况下都能获得最合适的指导,从而显著提高广泛任务的性能,而无需昂贵的微调。
4.2. Retrieval Augmented Generation
4.2. 检索增强生成
Retrieval Augmented Generation (RAG) is a technique for retrieving relevant documents for additional context before generating a response. It’s like giving the LLM a quick peek at specific reference material to help inform its answer. This keeps responses current and factual without needing to retrain the model.
检索增强生成(RAG) 是一种在生成响应之前检索相关文档以提供额外上下文的技术。这就像让 LLM 快速浏览特定参考资料以帮助其回答。这使得响应保持最新和事实准确,而无需重新训练模型。
For instance, on a support chatbot application, RAG could pull relevant help-desk wiki pages to inform the LLM’s answers.
例如,在支持聊天机器人应用程序中,RAG 可以提取相关的帮助台维基页面以告知 LLM 的答案。
This approach helps LLMs stay current and reduces hallucinations by grounding responses in retrieved facts. RAG is particularly handy for tasks that require updated or specialized knowledge without retraining the entire model.
这种方法有助于 LLM 保持最新并通过基于检索到的事实减少幻觉。RAG 特别适用于需要更新或专业知识的任务,而无需重新训练整个模型。
For example, suppose we are building a support chat for our product. In that case, we can use RAG to retrieve a relevant document from our helpdesk wiki, then provide it to an LLM agent and ask it to compose an answer based on the question and provide a document.
例如,假设我们正在为我们的产品构建支持聊天。在这种情况下,我们可以使用 RAG 从我们的帮助台维基中检索相关文档,然后将其提供给 LLM 代理,并要求它根据问题和提供的文档撰写答案。
There are three key pieces to look at while implementing RAG:
- Retrieval mechanism — While the traditional implementation of RAG involves retrieving a relevant document using a vector similarity search, sometimes it’s better or cheaper to use simpler methods such as keyword-based search (like BM-25).
- Indexed data structure —Indexing the entire document naively, without preprocessing, may limit the effectiveness of the retrieval process. Sometimes, we want to add a data preparation step, such as preparing a list of questions and answers based on the document.
- Metadata—Storing relevant metadata allows for more efficient referencing and filtering of information (e.g., narrowing down wiki pages to only those related to the user’s specific product inquiry). This extra data layer streamlines the retrieval process.
在实施 RAG 时需要注意三个关键点:
- 检索机制——虽然 RAG 的传统实现涉及使用向量相似性搜索检索相关文档,但有时使用更简单的方法(如基于关键字的搜索(如 BM-25)更好或更便宜。
- 索引数据结构——未经预处理地对整个文档进行索引可能会限制检索过程的有效性。有时,我们希望添加数据准备步骤,例如根据文档准备问题和答案列表。
- 元数据——存储相关元数据可以更有效地引用和过滤信息(例如,将维基页面缩小到仅与用户的特定产品查询相关的页面)。这个额外的数据层简化了检索过程。
4.3. Providing relevant context
4.3. 提供相关上下文
The context information relevant to your agent can vary. Although it may seem beneficial, providing the model (like the “unskilled worker”) with too much information can be overwhelming and irrelevant to the task. Theoretically, this causes the model to learn irrelevant information (or token connections), which can lead to confusion and hallucinations.
与代理相关的上下文信息可能会有所不同。尽管这似乎是有益的,但为模型(如“无技能的工人”)提供过多信息可能会让人不知所措且与任务无关。从理论上讲,这会导致模型学习无关的信息(或标记连接),这可能会导致混淆和幻觉。
When Gemini 1.5 was released and introduced as an LLM that could process up to 10M tokens, some practitioners questioned whether the context was still an issue. While it’s a fantastic accomplishment, especially for some use cases (such as chat with PDFs), it’s still limited, especially when reasoning over various documents.
当 Gemini 1.5 发布并作为可以处理多达 10M 标记的 LLM 介绍时,一些从业者质疑上下文是否仍然是一个问题。虽然这对于某些用例(如与 PDF 聊天)来说是一个了不起的成就,但它仍然有限,尤其是在对各种文档进行推理时。
Compacting the prompt and providing the LLM agent with only relevant information is crucial. This reduces the processing power the model invests in irrelevant tokens, improves the quality, optimizes the latency, and reduces the cost.
压缩提示并仅向 LLM 代理提供相关信息至关重要。这减少了模型在无关标记上投入的处理能力,提高了质量,优化了延迟并降低了成本。
There are many tricks to improve the relevancy of the provided context, most of which relate to how you store and catalog your data.
有许多技巧可以提高提供上下文的相关性,其中大部分与您存储和编目数据的方式有关。
For RAG applications, it’s handy to add a data preparation that shapes the information you store (e.g., questions and answers based on the document, then providing the LLM agent only with the answer; this way, the agent gets a summarized and shorter context), and use re-ranking algorithms on top of the retrieved documents to refine the results.
对于 RAG 应用程序,添加一个数据准备步骤是很有帮助的,该步骤可以塑造您存储的信息(例如,根据文档准备问题和答案,然后仅向 LLM 代理提供答案;这样,代理就会得到一个总结和更短的上下文),并在检索到的文档上使用重新排序算法来优化结果。
“Data fuels the engine of LLM-native applications. A strategic design of contextual data unlocks their true potential.”
“数据为 LLM 原生应用程序提供动力。上下文数据的战略设计释放了它们的真正潜力。”
Conclusion and Implications
结论和影响
The LLM Triangle Principles provide a structured approach to developing high-quality LLM-native applications, addressing the gap between LLMs’ enormous potential and real-world implementation challenges. Developers can create more reliable and effective LLM-powered solutions by focusing on 3+1 key principles—the Model, Engineering Techniques, and Contextual Data—all guided by a well-defined SOP.
LLM 三角原则提供了一种结构化的方法来开发高质量的 LLM 原生应用程序,解决了 LLM 巨大潜力与现实世界实施挑战之间的差距。通过专注于 3+1 个关键原则——模型、工程技术和上下文数据——并以定义明确的SOP为指导,开发人员可以创建更可靠和有效的 LLM 驱动解决方案。
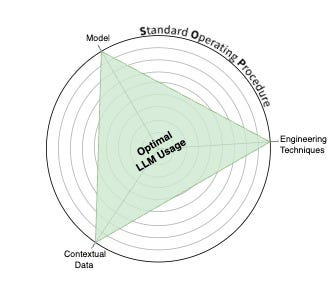
The LLM Triangle Principles. (Image by author)
LLM 三角原则。
Key takeaways
-
Start with a clear SOP: Model your expert’s cognitive process to create a step-by-step guide for your LLM application. Use it as a guide while thinking of the other principles.
-
Choose the right model: Balance capabilities with cost, and consider starting with larger models before potentially moving to smaller, fine-tuned ones.
-
Leverage engineering techniques: Implement LLM-native architectures and use agents strategically to optimize performance and maintain control. Experiment with different prompt techniques to find the most effective prompt for your case.
-
Provide relevant context: Use in-context learning, including RAG, when appropriate, but be cautious of overwhelming the model with irrelevant information.
-
Iterate and experiment: Finding the right solution often requires testing and refining your work. I recommend reading and implementing the “Building LLM Apps: A Clear Step-By-Step Guide” tips for a detailed LLM-Native development process guide.
-
从明确的 SOP 开始:对专家的认知过程进行建模,以创建 LLM 应用程序的逐步指南。在考虑其他原则时将其用作指南。
-
选择合适的模型:在能力与成本之间取得平衡,考虑从较大的模型开始,然后可能转向较小的微调模型。
-
利用工程技术:实施 LLM 原生架构并战略性地使用代理以优化性能并保持控制。尝试不同的提示技术,以找到最有效的提示。
-
提供相关上下文:在适当的时候使用上下文学习,包括 RAG,但要注意不要用无关信息压倒模型。
-
迭代和实验:找到合适的解决方案通常需要测试和改进您的工作。我建议阅读和实施“构建 LLM 应用程序:清晰的逐步指南” 提供的详细 LLM 原生开发过程指南。
By applying the LLM Triangle Principles, organizations can move beyond a simple proof-of-concept and develop robust, production-ready LLM applications that truly harness the power of this transformative technology.
通过应用 LLM 三角原则,组织可以超越简单的概念验证,开发出真正利用这种变革性技术力量的强大、生产就绪的 LLM 应用程序。