Shortly after I started blogging, because I was a college student and had nothing better to do, I set a goal to write every week. I started in September 2013 and wrote around 150 posts between then and when I started working at Wave. (At that point I stopped having nothing better to do, so my blogging frequency tanked.)
在我开始写博客后不久,因为我当时是个大学生,没什么更好的事情可做,我就给自己定了每周写作的目标。我从2013年9月开始,在那之后到我开始在 Wave 工作期间,写了大约150篇文章。(到那时我就不再是无所事事了,所以我写博客的频率骤降。)
The outcomes of these 150 posts were extremely skewed:
-
Two made it big on the Hacker News frontpage (What happened to all the non-programmers and Readability, hackability, and abstraction).
-
After seeing the second post on HN, Dan Luu subscribed to my blog and started submitting lots of my posts. This caused an additional ~5 posts to get decent traction, which resulted in my first wave of subscribers that I didn’t know personally, and provided a lot of motivation to keep writing. Dan and I also eventually became good friends.
-
The other ~95% of posts were completely forgettable.
这150篇文章的结果极度不均衡
- 有两篇在 Hacker News 首页大获成功(《非程序员都去哪了》和《可读性、可黑客性和抽象性》)。
- 在 HN 上看到第二篇文章后, Dan Luu 订阅了我的博客,并开始大量提交我的文章。这使得又有约5篇文章获得了不错的关注度,为我带来了第一批不是我私人认识的订阅者,也给了我继续写作的强大动力。 Dan 和我最终也成为了好朋友。
- 其余约95%的文章则完全无人问津。
This is a pretty typical spread of outcomes for blog writers: a few smash hits and a lot of clunkers. Eight years later, I’ve built a good enough intuition for what posts will resonate with people that I can now mostly avoid writing complete clunkers, but even so, my few best recent posts (In defense of blub studies and You don’t need to work on hard problems) have been much more successful than the others, both in terms of being shared widely, and getting feedback like “this really influenced how I think.”✻✻ Also feedback like “this article is MBA-tier horseshit,” but I try to look on the bright side.
这种结果分布对博客作者来说相当典型:少数爆款和大量平庸之作。八年后的今天,我已经建立了足够好的直觉,能够判断哪些文章会引起共鸣,所以现在基本上可以避免写出完全无人问津的文章。即便如此,我最近几篇最好的文章(《为 blub 研究辩护》和《你不需要解决难题》)仍然比其他文章成功得多,无论是在广泛传播方面,还是在获得”这篇文章真的影响了我的思考方式”这样的反馈方面。✻✻ 当然,也有”这文章就是 MBA 级别的狗屁”这样的反馈,不过我总是尽量往好处想。
This type of statistical distribution of outcomes is called heavy-tailed, because outcomes in the “tail” (i.e. ones that are far better than the typical outcome) have a relatively high chance of occurring, making the tail “heavy.” When I write blog posts, each post is a sample from the heavy-tailed distribution of blog post outcomes.
这种统计学上的结果分布被称为”重尾分布”,因为在”尾部”(即远好于典型结果的那些)出现的概率相对较高,使得尾部变得”沉重”。当我写博客文章时,每篇文章都是从博客文章结果的重尾分布中抽取的一个样本。
You can most easily see the difference between a heavy-tailed and light-tailed distribution on a plot. Here’s a plot comparing a heavy-tailed and light-tailed distribution with identical means and standard deviations, chosen to be similar to the distribution of household income in the US (median = 600,000):
你可以最容易地在一个图表上看到重尾分布和轻尾分布之间的区别。这里有一个图表,比较了一个重尾分布和轻尾分布,它们具有相同的平均值和标准差,选择的数值与美国家庭收入分布相似(中位数 = 60,000美元;99百分位 = 600,000美元):
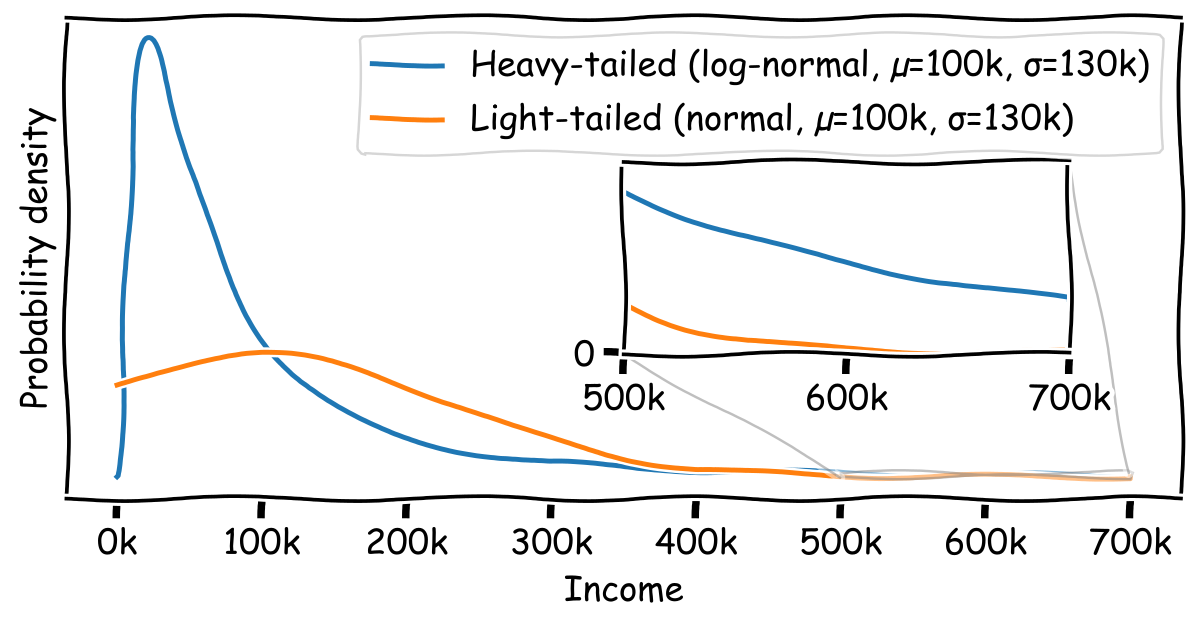
Figure 1. As the inset shows, extreme outliers are much more probable, relatively speaking, with the heavy-tailed distribution. (code)
图1。如插图所示,在重尾分布中,极端异常值出现的概率相对来说要高得多
Heavy-tailed distributions are really unintuitive to most people, since all the “action” happens in the tiny fraction of samples that are outliers. But lots of important things in life are outlier-driven, like jobs, employees, or relationships, and of course the most important thing of all, blog posts.
对大多数人来说,重尾分布真的很难直观理解,因为所有的”戏剧性”都发生在那一小部分异常样本中。但生活中许多重要的事情都是由异常值驱动的,比如工作、员工或人际关系,当然还有最重要的——博客文章。
Because heavy-tailed distributions are unintuitive, people often make serious mistakes when trying to sample from them:
- They don’t draw enough samples
- They underestimate how good of an outcome it’s possible to get
- They find it hard to tell whether they’re following a strategy that will eventually work or not, so they get incredibly demoralized.
正因为重尾分布不直观,人们在尝试从中取样时经常会犯严重的错误:
- 他们没有抽取足够多的样本
- 他们低估了可能获得的最好结果
- 他们很难判断自己是否在遵循一个最终会奏效的策略,因此变得极度沮丧。
If you’re aware of when you’re working on something that involves sampling from a heavy-tailed distribution, you can avoid those mistakes and end up with much better outcomes.
如果你意识到自己正在处理的事情涉及从重尾分布中取样,你就可以避免这些错误,最终获得更好的结果。
As a rule of thumb, a heavy-tailed distribution is one where the top few percent of outcomes are a large multiple of the typical or median outcome. A classic example would be Vilfredo Pareto’s finding that about 80% of Italy’s land was owned by 20% of the population. It turns out that this happens across many other domains, too—a phenomenon called the Pareto principle or the 80-20 rule.
根据经验,重尾分布是指前几个百分点的结果是典型或中位数结果的很大倍数。一个经典的例子是维尔弗雷多·帕累托发现,意大利约80%的土地由20%的人口拥有。事实证明,这种情况在许多其他领域也存在——这种现象被称为帕累托原理或80-20法则。
Some examples of heavy and light tails:
-
Income is heavy-tailed: the median person globally lives on 45,000, almost 20× more.
-
Height is light-tailed: the tallest people are only a few feet taller than average. If height followed the same distribution as income, Elon Musk, who made $121b in 2021, would be about 85,000 km tall, or about ¼ of the distance from the earth to the moon.
-
Twitter followers are heavy-tailed: in 2013, the median active Twitter poster had 61 followers, while the top 1% had almost 3,000.
-
Performance at most athleticism-based sports is light-tailed. For the 100m sprint, the current world record from Usain Bolt is 9.58 seconds, while “a non-elite athlete can run 100m in 13-14 seconds.”†† Note that some statistics based on ranking performance can still be heavy-tailed: for example, Usain Bolt has orders of magnitude more Olympic gold medals than a typical non-elite athlete.
-
The cost-effectiveness of global health interventions is heavy-tailed: as measured by the Disease Control Priorities project, the most cost-effective intervention was about 3× as cost-effective as the 10th-most cost-effective, and 10× the 20th-most cost-effective.‡‡ Disease Control Priorities, third edition, page 149, figure 7.1.
以下是一些重尾和轻尾分布的例子:
- 收入是重尾分布:全球中位数人的年收入为2,500美元,而前1%的人年收入为45,000美元,几乎是20倍。
- 身高是轻尾分布:最高的人只比平均身高高几英尺。如果身高遵循与收入相同的分布,那么2021年赚了1210亿美元的埃隆·马斯克将会有约85,000公里高,大约是地球到月球距离的四分之一。
- Twitter 粉丝数是重尾分布:2013年,活跃 Twitter 发帖者的中位数粉丝数为61,而前1%的人拥有近3,000名粉丝。
- 大多数基于运动能力的体育项目表现是轻尾分布。以100米短跑为例,尤塞恩·博尔特创造的当前世界纪录是9.58秒,而”非精英运动员可以在13-14秒内跑完100米”。需要注意的是,一些基于排名表现的统计数据仍可能是重尾分布:例如,尤塞恩·博尔特获得的奥运金牌数量比普通非精英运动员多出几个数量级。
- 全球卫生干预措施的成本效益是重尾分布:根据疾病控制优先项目的测量,最具成本效益的干预措施比第10位成本效益高的干预措施高出约3倍,比第20位高出10倍。
Light-tailed distributions most often occur because the outcome is the result of many independent contributions, while heavy-tailed distributions often arise from the result of processes that are multiplicative or self-reinforcing.§§ More formally: the central limit theorem means that the sum of independent contributions will be approximately normally distributed, and normal distributions are extremely light-tailed. An easy extension of the theorem says that the product of independent variables will be log-normally distributed, which is much more heavy-tailed. The type of self-reinforcing process I’m referring to is a preferential attachment process which usually generates a power law distribution, which is even heavier-tailed than the log-normal. For example, the richer you are, the easier it is to earn more money. The more Twitter followers you have, the more retweets you’ll get, and the more you’ll be exposed to new potential followers. The cost-effectiveness of a global health intervention comes from multiplying many different variables (how bad the disease you’re fighting is, how much of an impact the intervention has on the disease, how costly doing the intervention for one person is), each of which itself is the product of several other factors.
轻尾分布最常见的原因是结果来自许多独立贡献的总和,而重尾分布通常源于乘法或自我强化的过程。更正式地说:中心极限定理意味着独立贡献的总和将近似正态分布,而正态分布是极度轻尾的。该定理的一个简单扩展表明,独立变量的乘积将呈对数正态分布,这种分布更加重尾。我所指的自我强化过程是一种优先连接过程,通常会产生幂律分布,这种分布比对数正态分布更加重尾。例如,你越富有,就越容易赚更多的钱。你的 Twitter 粉丝越多,你就会获得更多的转发,也就会接触到更多潜在的新粉丝。全球卫生干预措施的成本效益来自于多个不同变量的乘积(你所对抗的疾病有多严重,干预措施对疾病的影响有多大,为一个人实施干预措施的成本有多高),而每个变量本身又是其他几个因素的乘积。
Notably, in a light-tailed distribution, outliers don’t matter much. The 1% of tallest people are still close enough to the average person that you can safely ignore them most of the time. By contrast, in a heavy-tailed distribution, outliers matter a lot: even though 90% of people live on less than $15,000 a year, there are large groups of people making 1,000 times more. Because of this, heavy-tailed distributions are much less intuitive to understand or predict.
值得注意的是,在轻尾分布中,异常值并不那么重要。最高的1%的人仍然与普通人足够接近,以至于你大多数时候可以安全地忽略他们。相比之下,在重尾分布中,异常值非常重要:尽管90%的人年收入不到15,000美元,但仍有大群人的收入是这个数字的1,000倍。正因为如此,重尾分布更难以直观理解或预测。
That’s unfortunate, since according to me (and the Pareto Principle), most important things in life are heavy-tailed. For example:
这是不幸的,因为根据我(和帕累托原理)的观点,生活中大多数重要的事情都是重尾分布的。例如:
-
Goodness of jobs. This is clearest for dimensions like salary that are measurable, but in my experience it’s also true of less-measurable dimensions like how much you’ll learn or whether you’ll be miserable because of dysfunctional company culture. (Note that which jobs are outliers for you depends on your values, which differ a lot from person to person! For example, working at Wave was an outlier for me, but hasn’t been for everyone.)
-
工作的好坏。这在薪水等可测量的维度上最为明显,但根据我的经验,在一些不太容易测量的维度上也是如此,比如你能学到多少,或者是否会因为公司文化的问题而感到痛苦。(注意,哪些工作对你来说是异常值取决于你的价值观,而这因人而异!例如,在 Wave 工作对我来说是一个异常值,但并非对每个人都是如此。)
-
Effectiveness of (many types of) knowledge workers. Dan Luu writes: “At places I’ve worked, I track what causes decisions to happen, who’s actually making things happen, etc., and there are a very small number of people (on the order of a few percent), who are really critical to the company’s effectiveness.”
-
(许多类型的)知识工作者的效率。Dan Luu 写道:“在我工作过的地方,我会追踪是什么导致了决策的发生,谁在真正推动事情发展等,结果发现只有极少数人(大约几个百分点)对公司的效率真正至关重要。”
-
Influentialness of ideas. The top 100 most-cited papers have over 12,000 citations each, while the median paper seems to have about one citation.
-
想法的影响力。被引用最多的前100篇论文每篇都有超过12,000次引用,而中位数论文似乎只有大约1次引用。
-
Quality of romantic partnerships. For example, in the US today, almost 50% of partnerships end in divorce, whereas the 99th percentile probably involves the couple being (on average) extremely happy with each other for 50+ years. In other contexts, this seems likely to be even more true; for example, in some low-income countries with regressive gender norms, over 25% of women who have ever had a partner experience domestic violence each year, which probably makes the average partnership extremely bad.‖‖ Several draft readers suggested that arranged-marriage societies have similar rates of marital satisfaction to love marriages, which was evidence against this. I couldn’t immediately find high-quality studies on the topic; every study I found had a very small sample size and many had severe grammatical errors in their abstracts, which, while not directly related to the study’s quality, did not inspire confidence. Either way, even if it’s the case that arranged and love marriages lead to similar satisfaction on average, this isn’t very good evidence against heavy-tailed-ness since the average person in a love marriage almost certainly hasn’t found a partner who’s top-1% for them.
-
浪漫伴侣关系的质量。例如,在当今美国,近50%的伴侣关系以离婚告终,而排在前1%的伴侣可能(平均而言)在50多年里彼此都非常幸福。在其他背景下,这种情况似乎更加明显;例如,在一些性别规范落后的低收入国家,每年有超过25%曾有过伴侣的女性遭受家庭暴力,这可能使得平均伴侣关系极其糟糕。‖‖ 一些草稿读者提出,包办婚姻社会的婚姻满意度与自由恋爱婚姻相似,这似乎与我的观点相悖。我没有立即找到关于这个话题的高质量研究;我找到的每项研究样本量都很小,而且许多研究的摘要中存在严重的语法错误,这虽然与研究质量没有直接关系,但也不能让人信服。无论如何,即使包办婚姻和自由恋爱婚姻平均满意度相似,这也不能很好地反驳重尾分布的观点,因为自由恋爱婚姻中的普通人几乎肯定没有找到对他们来说最适合的前1%的伴侣。
-
Success of startups. In November 2021, the total value of all 3,200 Y Combinator-funded companies was 100b, Stripe: 80b, Doordash: 40b). The mean non-top-5 company was worth ~$60m, or ~1% of a top-5, so the median was likely even less than that.
-
创业公司的成功。2021年11月,所有3,200家由 Y Combinator 资助的公司的总价值为5750亿美元,其中前5家(或前0.2%)占了约65%(Airbnb:1000亿美元,Stripe:1000亿美元,Coinbase:800亿美元,Doordash:500亿美元,Instacart:400亿美元)。非前5名公司的平均价值约为6000万美元,或前5名的约1%,所以中位数可能更低。
-
Business outcomes of projects within a company. The clearest data on this comes from software companies measuring effect sizes of A/B tests. For example, a team at Microsoft Research measured the distribution of impact of experiments on Bing and found that “many experiments have very small measured deltas, while a handful show substantial gains.” An analytics company, Optimizely, also found that their customers’ A/B tests followed a similarly heavy-tailed distribution.
-
公司内部项目的商业成果。关于这一点,最清晰的数据来自软件公司对 A/B 测试效果大小的测量。例如,微软研究院的一个团队测量了 Bing 上实验影响的分布,发现”许多实验测得的变化很小,而少数实验显示出显著的收益。“分析公司 Optimizely 也发现,他们客户的 A/B 测试遵循类似的重尾分布。
Anecdotally, based on my experience at Wave, the same effect seems to hold for longer-running projects that are less easy to quantify.¶¶ In fact, I’d expect these to be more heavy-tailed since in regimes where it’s hard to quantify results, people end up working on more things that have basically no impact. People who start doing A/B tests commonly say that they learn that the things that move their metrics are very different from what they would have expected a priori. The dynamics here are similar to those for startups, since many projects within companies are like mini-startups.
根据我在 Wave 的经验,这种效应似乎也适用于那些更长期且不易量化的项目。¶¶ 事实上,我预计这些项目会更加重尾,因为在难以量化结果的情况下,人们最终会做更多基本上没有影响的事情。开始进行 A/B 测试的人通常会说,他们发现真正能改变指标的因素与他们事先的预期大不相同。这里的动态与创业公司类似,因为公司内部的许多项目就像小型创业。
-
Impact of philanthropic projects. The Open Philanthropy Project argues for a “hits-based giving” approach: “We suspect that high-risk, high-reward philanthropy could be described as a ‘hits business,’ where a small number of enormous successes account for a large share of the total impact — and compensate for a large number of failed projects.”
-
慈善项目的影响。开放慈善项目提倡一种”基于命中率的捐赠”方法:“我们怀疑高风险、高回报的慈善事业可以被描述为一种’命中率业务’,其中少数巨大的成功占据了总体影响的大部分——并弥补了大量失败项目的损失。”
-
Life decisions like where to live. For example, at least pre-COVID, if you were a software engineer, moving to San Francisco would have been likely to put you on a very different career trajectory than almost any other city because there are so many more jobs available, and also would have made you much more likely to e.g. start a company.✻✻✻✻ Much like jobs or partners, different cities are outliers for different people, and there are probably many people for whom the distribution is more thin-tailed, for instance because they’re in a less-concentrated industry. If you were a rationalist, effective altruist or other weird Internet intellectual, it was likely to have a similar effect due to being “global weird HQ.”
-
生活决策,比如选择居住地。例如,至少在新冠疫情之前,如果你是一名软件工程师,搬到旧金山可能会让你的职业轨迹与其他几乎任何城市都大不相同,因为那里有更多的工作机会,而且也会大大增加你创办公司的可能性。✻✻✻✻ 就像工作或伴侣一样,不同的城市对不同的人来说都是异常值,对许多人来说,这种分布可能更加薄尾,例如因为他们所在的行业不那么集中。如果你是一个理性主义者、有效利他主义者或其他奇特的互联网知识分子,由于旧金山是”全球怪人总部”,可能会产生类似的效果。
-
Usefulness of new activities to try. In my teens and early 20s, I tried a large number of different activities. Most of them were completely forgettable, but the top few were extremely valuable. For example, one time I allowed a housemate to convince me to go to a contra dance. I really liked it and became a serious contra dancer, which was probably the activity that contributed the most to my happiness and wellbeing from ages ~13-21 as well as helping me meet a large number of friends and multiple romantic partners.
-
尝试新活动的有用性。在我十几岁和二十岁初期,我尝试了大量不同的活动。其中大多数都完全不值得记住,但最好的几个却极其有价值。例如,有一次我被室友说服去参加了一场康特拉舞。我非常喜欢它,并成为了一名认真的康特拉舞者,这可能是从13岁到21岁左右对我的幸福感和健康贡献最大的活动,同时也帮助我结识了大量朋友和多个浪漫伴侣。
Hopefully that’s enough examples to convince you that heavy-tailed distributions are absolutely everywhere.
希望这些例子足以让你相信,重尾分布确实无处不在。
The most important thing to remember when sampling from heavy-tailed distributions is that getting lots of samples improves outcomes a ton.
在从重尾分布中取样时,最重要的是要记住,获取大量样本可以极大地改善结果。
In a light-tailed context—say, picking fruit at the grocery store—it’s fine to look at two or three apples and pick the best-looking one. It would be completely unreasonable to, for example, look through the entire bin of apples for that one apple that’s just a bit better than anything you’ve seen so far.
在轻尾分布的情况下——比如在杂货店挑选水果——看两三个苹果然后选最好看的那个就可以了。要是为了找到一个比你目前看到的所有苹果都稍微好一点的苹果而翻遍整箱苹果,那就完全不合理了。
In a heavy-tailed context, the reverse is true. It would be similarly unreasonable to, say, pick your romantic partner by taking your favorite of the first two or three single people you run into. Every additional sample you draw increases the chance that you get an outlier. So one of the best ways to improve your outcome is to draw as many samples as possible.
在重尾分布的情况下,情况恰恰相反。比如说,从你遇到的头两三个单身人士中选择你最喜欢的作为你的浪漫伴侣,这同样是不合理的。你抽取的每一个额外样本都会增加你获得异常值的机会。因此,改善结果的最佳方法之一就是尽可能多地抽取样本。
As the dating example shows, most people have some intuition for this already, but even so, it’s easy to underrate this and not meet enough people. That’s because the difference between, say, a 90th and 99th-percentile relationship is relatively easy to observe: it only requires considering 100 candidates, many of whom you can immediately rule out. What’s harder to observe is the difference between the 99th and 99.9th, or 99.9th and 99.99th percentile, but these are likely to be equally large. Given the stakes involved, it’s probably a bad idea to stop at the 99th percentile of compatibility.
正如约会的例子所示,大多数人已经对此有一些直觉,但即便如此,人们还是很容易低估这一点而没有结识足够多的人。这是因为,比如说,第90百分位和第99百分位的关系之间的差异相对容易观察到:只需考虑100个候选人,其中许多人你可以立即排除。更难观察到的是第99百分位和第99.9百分位,或第99.9百分位和第99.99百分位之间的差异,但这些差异可能同样巨大。考虑到所涉及的风险,在兼容性达到第99百分位时就停止可能是个坏主意。
This means that sampling from a heavy-tailed distribution can be extremely demotivating, because it requires doing the same thing, and watching it fail, over and over again: going on lots of bad dates, getting pitched by lots of low-quality startups, etc. An important thing to remember in this case is to trust the process and not take individual failures, or even large numbers of failures, as strong evidence that your overall process is bad.
这意味着从重尾分布中取样可能会让人极度沮丧,因为它需要反复做同样的事情,并看着它一次又一次地失败:经历许多糟糕的约会,被许多低质量的创业公司推销等。在这种情况下,重要的是要记住信任这个过程,不要把个别失败,甚至大量失败,视为你整个过程有问题的强有力证据。
When I was doing my first systematic engineering hiring process for Wave—before we’d hired any great people in a non-ad-hoc way—I found it exhausting to give candidates the same interview over and over again and rejecting every one. As a result, we originally set our bar lower than we should have. After hiring some really great folks through that process, I finally became intuitively convinced that the hiring work we were doing was valuable, and became much happier to spend a lot of time and effort on hiring, because I knew it would eventually pay off. After that, we ended up raising our hiring bar over time.
当我为 Wave 进行第一次系统的工程招聘过程时——在我们以非临时方式雇佣任何优秀人才之前——我发现一遍又一遍地给候选人相同的面试并拒绝每一个人是非常令人疲惫的。结果,我们最初设定的标准比应该的要低。通过那个过程雇佣了一些真正优秀的人之后,我终于直觉地确信我们所做的招聘工作是有价值的,并且更乐意花大量时间和精力在招聘上,因为我知道这最终会有回报。之后,我们逐渐提高了招聘标准。
Often, you’ll have a choice between spending time on optimizing one sample or drawing a second sample—for instance, editing a blog post you’ve already written vs. writing a second post, or polishing a message on a dating app vs. messaging a second person. Some amount of optimization is worth it, but in my experience, most people are way over-indexed on optimization and under-indexed on drawing more samples.
通常,你会面临在优化一个样本和抽取第二个样本之间做选择——例如,编辑你已经写好的博客文章 vs. 写第二篇文章,或者在约会应用上精心修饰一条消息 vs. 给第二个人发消息。一定程度的优化是值得的,但根据我的经验,大多数人过度关注优化而忽视了抽取更多样本。
This is similar to how venture capitalists are often willing to invest in the best companies at absurd-seeming valuations. The logic goes that if the company is a “winner,” the most important thing is to have invested at all and the valuation won’t really matter. So it’s not worth it to the VC to try very hard to optimize the valuation at which they invest.
这类似于风险投资家经常愿意以看似荒谬的估值投资最好的公司。逻辑是,如果这家公司是”赢家”,最重要的是有投资,估值并不真的重要。所以对风险投资家来说,努力优化他们投资时的估值并不值得。
Another consequence of the numbers game is that the strategy that you use to filter your samples is very important: for example, as an investor, one of the silliest ways you can lose money is to get pitched by a startup, pass on them because you think they’re bad, and then see them get 100× more valuable. Because of this, it’s very important for your filters to be as tightly correlated with what you actually care about as possible, so that you don’t rule candidates out for bad reasons.†††† To some extent, it’s useful not to rule out candidates for silly reasons regardless of whether the distribution you’re sampling from is heavy-tailed. But it’s much more important in a heavy-tailed context, because the difference between the best and second-best candidate is likely to be much larger, so if you pass on the best candidate, you’re giving up more value.
数字游戏的另一个结果是,你用来过滤样本的策略非常重要:例如,作为投资者,最愚蠢的亏钱方式之一是被一家创业公司推销,因为你认为它们不好而放弃,然后看到它们的价值增长了100倍。因此,让你的过滤器尽可能紧密地与你真正关心的事物相关联非常重要,这样你就不会因为糟糕的理由而排除候选者。†††† 在某种程度上,无论你从什么分布中取样,不因为愚蠢的理由排除候选者都是有用的。但在重尾分布的情况下,这一点更加重要,因为最佳候选者和次佳候选者之间的差距可能会更大,所以如果你放弃了最佳候选者,你就放弃了更多价值。
A subtlety here is that the traits that make a candidate a potential outlier are often very different from the traits that would make them “pretty good,” so improving your filtering process to produce more “pretty good” candidates won’t necessarily increase the rate of finding outliers, and might even decrease it. Because of this, it’s important to filter for “maybe amazing,” not “probably good.” For example, this is why Y Combinator doesn’t filter very much on whether a startup’s idea seems good. Bad-sounding startup ideas are probably less-successful on average, but more likely to be outliers:
这里的一个微妙之处在于,使候选者成为潜在异常值的特征通常与使他们”相当不错”的特征非常不同,所以改进你的过滤过程以产生更多”相当不错”的候选者不一定会增加找到异常值的比率,甚至可能会降低它。因此,重要的是要过滤”可能惊人”,而不是”可能不错”。例如,这就是为什么 Y Combinator 不太过滤创业公司的想法是否看起来不错。听起来不好的创业想法平均来说可能不太成功,但更有可能成为异常值:
The best startup ideas seem at first like bad ideas. I’ve written about this before: if a good idea were obviously good, someone else would already have done it. So the most successful founders tend to work on ideas that few beside them realize are good. Which is not that far from a description of insanity, till you reach the point where you see results.
The first time Peter Thiel spoke at YC he drew a Venn diagram that illustrates the situation perfectly. He drew two intersecting circles, one labelled “seems like a bad idea” and the other “is a good idea.” The intersection is the sweet spot for startups.
This concept is a simple one and yet seeing it as a Venn diagram is illuminating. It reminds you that there is an intersection—that there are good ideas that seem bad. It also reminds you that the vast majority of ideas that seem bad are bad.
最好的创业想法一开始看起来像是坏主意。我以前写过这个:如果一个好主意显而易见地好,别人早就已经做了。所以最成功的创始人往往在做那些除了他们自己之外很少有人意识到是好主意的事情。这与疯狂的描述并不遥远,直到你看到结果为止。
Peter Thiel 第一次在 YC 演讲时画了一个完美诠释这种情况的维恩图。他画了两个相交的圆,一个标记为”看起来像个坏主意”,另一个标记为”是个好主意”。交集就是创业的最佳点。
这个概念很简单,但将其视为维恩图却很有启发性。它提醒你存在一个交集——有些看起来不好的想法实际上是好的。它也提醒你,绝大多数看起来不好的想法确实是不好的。
Instead, Y Combinator mostly ignores idea quality and tries to find high-quality founding teams who can iterate on the idea quickly in response to user feedback.
相反,Y Combinator 大多忽略了想法的质量,而是试图找到高质量的创始团队,这些团队能够根据用户反馈快速迭代想法。
This has worked well for them: when the Airbnb founders pitched them on an app for hosting strangers in your apartment, the YC partners thought that the idea was terrible and would never work, but were impressed by the team’s determination (in particular making ends meet by selling politically themed cereal) and decided to fund them anyway. In this case, the partners were catastrophically wrong about the idea being bad, but fortunately it didn’t matter because they had correctly decided not to put much weight on that as a signal. With a less disciplined evaluation process, they might have passed on Airbnb, which now comprises about 15% of the value of the YC portfolio (575b). Meanwhile, at least one successful VC passed on Airbnb specifically because they were “very suspect of this idea” and now keeps a box of politically-themed cereal in their office as a “reminder to back great entrepreneurs whenever they walk into our office regardless of what they pitch us on.”
这种方法对他们来说效果很好:当 Airbnb 的创始人向他们推销一个在你的公寓里接待陌生人的应用时,YC 的合伙人认为这个想法很糟糕,永远不会成功,但他们对团队的决心印象深刻(特别是通过销售政治主题的麦片来维持生计),并决定还是资助他们。在这个案例中,合伙人对这个想法是坏主意的判断是灾难性的错误,但幸运的是这并不重要,因为他们正确地决定不把太多权重放在这个信号上。如果评估过程不那么严格,他们可能就错过了 Airbnb,而现在 Airbnb 占 YC 投资组合价值的约15%(5750亿美元中的1000亿美元)。同时,至少有一家成功的风投公司因为”非常怀疑这个想法”而放弃了 Airbnb,现在他们在办公室里放了一盒政治主题的麦片,作为”无论创业者向我们推销什么,只要他们走进我们的办公室,我们就要支持优秀创业者的提醒”。
In other contexts, it’s very common for people sampling from heavy-tailed distributions to focus on “ruling out” candidates instead of “ruling in,” which is likely to be a bad approach for similar reasons. In dating, for instance, people often have some sort of checklist they want a potential partner to satisfy, where most of the checkboxes (say, professional background) rule out lots of people but are only weakly correlated with long-term compatibility. Sasha Chapin writes:
在其他情况下,从重尾分布中取样的人通常会专注于”排除”候选者而不是”纳入”,这可能出于类似的原因而是一种糟糕的方法。例如,在约会中,人们经常有一些他们希望潜在伴侣满足的清单,其中大多数选项(比如职业背景)会排除很多人,但与长期兼容性的相关性很弱。Sasha Chapin 写道:
Once, on a day where I felt like I knew something, I declared that I would be okay with dating anyone who wasn’t vegan or an actress. It was clear to me that cheeseburgers were crucial to my happiness, and that I’d have a hard time getting close to a professional emotion simulator. Now I have a wife who is both a vegan and an actress, with whom I’m extremely happy.
I can still recall, with shocking clarity, the moment three hours after I met my wife, when I offered her a piece of chicken. “Actually, I’m vegan,” she said. “Well,” I said to myself, “I suppose I am fucked now.” The night air was glimmering, love was all around, and I mentally edited out many chunks of animal protein in the future.
有一天,我觉得自己好像懂了些什么,就宣称我可以接受和任何不是素食主义者或演员的人约会。对我来说,很明显奶酪汉堡对我的幸福至关重要,而且我会很难亲近一个专业的情感模拟器。现在我有了一个既是素食主义者又是演员的妻子,我和她在一起非常幸福。
我仍然能以惊人的清晰度回忆起遇见妻子三小时后的那一刻,当时我给她递了一块鸡肉。“其实,我是素食主义者,“她说。“好吧,“我对自己说,“我想我现在完蛋了。“夜空闪烁,爱情无处不在,我在脑海中删除了未来许多块动物蛋白。
If you think of yourself as having a limited “filtering budget” to “spend” while dating (since you can only apply so many filters before your pool of eligible partners shrinks to zero), filtering for people from a small number of professions that comprise, say, 5% of the population is a poor use of that budget compared to using the same budget to find someone who is >95th percentile in, say, being able to talk through conflicts in a reasonable way.
如果你认为自己在约会时有一个有限的”过滤预算”可以”花费”(因为你只能应用这么多过滤条件,否则你的潜在伴侣池就会缩小到零),那么相比于用同样的预算来找一个在某方面(比如能够以合理的方式讨论冲突)处于前5%的人,过滤出来自占人口5%的少数职业的人是对这个预算的糟糕使用。
The difficulty with the latter is that it’s much faster to filter people for profession than being good at reasonably talking through conflicts. In fact, it’s generally true that it’s easier to filter for downsides than upsides, because downsides are more legible. On a dating app, it’s easy to see whether someone is physically unattractive or has poor grammar, but very hard to see whether they’re >95th percentile at talking through conflicts. But in principle, unless you’re overwhelmed by the quantity of people willing to go on dates with you, you’re probably more constrained by filtering budget than by time, so it makes more sense to be less strict on checkboxes and spend that filtering on better-correlated things.‡‡‡‡ If you’re a woman on a dating app, you’re much more likely to be in the “overwhelmed by the quantity” scenario, which changes the trade-off. It seems to me like it should probably still be worth putting in effort to make sure your filters are highly-correlated with what you actually care about, but I can’t speak from personal experience here.
后者的困难在于,按职业过滤人要比判断一个人是否善于合理地讨论冲突要快得多。事实上,通常情况下,过滤缺点比过滤优点更容易,因为缺点更容易辨识。在约会应用上,很容易看出一个人是否外表不吸引人或语法糟糕,但很难看出他们在处理冲突方面是否处于前5%。但原则上,除非你被愿意和你约会的人数量压垮,否则你可能更受过滤预算的限制而不是时间的限制,所以在选项上不那么严格,而把过滤用在更相关的事情上更有意义。‡‡‡‡ 如果你是约会应用上的女性,你更可能处于”被数量压垮”的情况,这改变了权衡。在我看来,努力确保你的过滤器与你真正关心的事物高度相关可能仍然是值得的,但我在这方面没有个人经验可以分享。
Similarly, many hiring processes allow any interviewer to veto a hire, which selects for well-rounded people with no serious downsides, but many people I know who are outliers at their jobs have serious downsides that they’ve figured out how to work around. For example, Drew, the CEO of Wave, is by far the strongest leader I’ve worked with, but for a long time he had a way of thinking and communicating that was hard to understand for some people (while being an extremely good fit for others, like me). At Wave, Drew could work around this by only having people report directly to him if they’re good at understanding how he thinks, and having his direct reports act as “interpreters” to the rest of the company if necessary. But if he had interviewed for roles at another company, I think it’s quite likely that at least one of his interviewers would have found him hard to communicate with and would have rejected him based on this.
同样,许多招聘过程允许任何面试官否决一个候选人,这选择了没有严重缺点的全面发展的人,但我认识的许多在工作中表现出色的人都有严重的缺点,他们已经找到了如何绕过这些缺点的方法。例如,Wave 的 CEO Drew 是我共事过的最强大的领导者,但长期以来,他的思考和沟通方式对某些人来说很难理解(而对其他人,比如我,却非常合适)。在 Wave,Drew 可以通过只让那些善于理解他思维方式的人直接向他汇报来解决这个问题,并在必要时让他的直接下属充当公司其他人的”翻译”。但如果他去其他公司面试,我认为很可能至少有一个面试官会发现与他沟通困难,并基于此拒绝他。
One tricky thing about heavy-tailed distributions is that it can be difficult to know how good a really great outcome can get.
关于重尾分布的一个棘手问题是,很难知道一个真正好的结果能有多好。
This matters the most in cases where there’s a trade-off between exploration and exploitation—that is, between getting more value from your current sample, or drawing a new sample from the distribution. For example, this is true of jobs, hires (for some positions), or relationships: they get better over time as you invest in them, so you ideally want to have the same one for a very long time, which means stopping looking at some point. To make that decision, it’s important to know whether your current job/candidate/relationship is just 90th percentile (relatively easy to do better) or 99.9th (quite hard to do better).
这在存在探索和利用之间权衡的情况下最为重要——也就是说,在从当前样本获得更多价值和从分布中抽取新样本之间权衡。例如,这适用于工作、招聘(对某些职位)或关系:随着你对它们的投入,它们会随时间变得更好,所以理想情况下你希望长期保持同一个,这意味着在某个时点停止寻找。要做出这个决定,重要的是要知道你当前的工作/候选人/关系是仅仅处于第90百分位(相对容易做得更好)还是第99.9百分位(相当难做得更好)。
When I accepted my first job out of college, I thought it was great. The startup I worked for had a clear explanation of why they’d identified a market inefficiency that nobody else had, so it seemed likely to succeed. The founders seemed like they knew a lot of stuff, and I was getting to learn about cool machine learning and statistics stuff.
当我接受大学毕业后的第一份工作时,我认为它很棒。我工作的创业公司对他们如何发现了别人没有发现的市场低效有清晰的解释,所以看起来很可能会成功。创始人似乎懂很多东西,我也在学习很酷的机器学习和统计学知识。
Those things were all true, but it also had significant downsides. The company’s constraint wasn’t machine learning, it was sales, so my work wasn’t always very important. Their potential market size was limited unless they could eat many adjacent parts of the value chain. And while the founders were fairly competent, I learned a lot less from them than I did from other mentors I had later.
这些都是事实,但它也有显著的缺点。公司的瓶颈不是机器学习,而是销售,所以我的工作并不总是很重要。除非他们能吞并价值链的许多相邻部分,否则他们的潜在市场规模是有限的。虽然创始人相当能干,但我从他们那里学到的东西比我后来从其他导师那里学到的要少得多。
I don’t think it was super unreasonable even in retrospect to take that job, since I did a relatively systematic search, and it was my first job so I didn’t have a lot of experience knowing what to look for. But my point is that I had no idea how much better stuff there was out there.
回想起来,我认为接受那份工作并不是非常不合理,因为我进行了相对系统的搜索,而且那是我的第一份工作,所以我没有太多经验知道该寻找什么。但我的观点是,我完全不知道外面还有多少更好的东西。
I’ve observed many other people who seem like they could achieve an outlier outcome fall into the same trap of “settling”—in job searches, in interviews, in dating, and in any other heavy-tailed situation. On average, I expect most people would benefit from rejecting more early candidates in all of these.
我观察到许多其他看起来可能实现异常结果的人也陷入了同样的”安于现状”的陷阱——在找工作、面试、约会以及任何其他重尾分布的情况下。平均而言,我认为大多数人在所有这些情况下拒绝更多早期候选者会更有益。
One reason you might be reluctant to do this is the worry that, if your job/candidate/relationship is actually the best you can hope for and you reject them, you’ll never find another equally good one. For this, I think it’s helpful to cultivate an abundance mindset. If you found your current job after two months of searching, then, unless you did something hard-to-replicate during those two months (e.g. call in a bunch of favors that you no longer have the social capital to do again), you should expect to be able to find an equally good opportunity in the future by putting in an equal amount of work.
你可能不愿意这样做的一个原因是担心,如果你的工作/候选人/关系实际上是你能期望的最好的,而你拒绝了他们,你就再也找不到同样好的了。对此,我认为培养一种丰富心态是有帮助的。如果你在搜索两个月后找到了当前的工作,那么,除非你在那两个月里做了一些难以复制的事情(例如,利用了一堆你现在已经没有社交资本再次做到的人情),你应该期望在未来通过投入同等的工作量能找到同样好的机会。
Of course, that’s just a prior that you should update away from if your current job is an outlier. But most people are much more likely to overestimate the outlierhood of their current job than underestimate it.
当然,这只是一个先验,如果你当前的工作是一个异常值,你应该更新这个观点。但大多数人更有可能高估而不是低估他们当前工作的异常性。
Note that this relies on you having a reasonable view on what an outlier would be. For example, if you think that an outlier job would be one in which you never have to do anything boring, you’ll incorrectly have doubts about every job because you’re holding jobs to an unreasonable standard—both in the sense that your expectations of non-boringness are too high, and there are other things that matter in addition to non-boringness.
请注意,这依赖于你对什么是异常值有一个合理的看法。例如,如果你认为异常值工作是一个你永远不需要做任何无聊事情的工作,你会错误地对每份工作都产生怀疑,因为你对工作的要求标准不合理——既是因为你对非无聊性的期望太高,也是因为除了非无聊性之外还有其他重要的因素。
To avoid this problem, it’s helpful to think ahead about what you’d expect a potential outlier to look like, instead of trying to think ad-hoc about “is this a potential outlier?” for each candidate. Of course, that’s hard! I actually don’t think I’ve done a very good job of this myself, but one thing I’ve found helpful is to ask other people what outliers have looked like based on their experience. If you’re trying to find a romantic partner, you could ask your friends who are the happiest in their relationships what makes their relationship an outlier. If hiring for a new role, you could ask colleagues who have worked with great people in that role.
为了避免这个问题,提前思考你期望的潜在异常值会是什么样子会很有帮助,而不是对每个候选者临时思考”这是潜在的异常值吗?“。当然,这很难!实际上我认为我自己在这方面做得并不是很好,但我发现一件有帮助的事是询问其他人,根据他们的经验,异常值是什么样子的。如果你正在寻找一个浪漫伴侣,你可以问问你那些在关系中最幸福的朋友,是什么让他们的关系成为异常值。如果你在为一个新角色招聘,你可以问问在那个角色上与优秀人才共事过的同事。
The other hard part of sampling from a heavy-tailed distribution is that it’s hard to know whether your process is working (in the sense that you’ll eventually end up finding outliers at a good rate). Even if you’re following a good process for, say, interviewing job candidates, you should expect to interview lots of people who don’t meet your bar before finding someone great. Conversely, if you’re making a bad mistake, like screening out candidates who would have been outliers for silly reasons, it’s very hard to notice that you’re doing this since you’ll never get to observe the counterfactual where you hired them.
从重尾分布中取样的另一个困难之处在于,很难知道你的过程是否有效(即你最终是否能以良好的速率找到异常值)。即使你在遵循一个好的过程,比如说面试求职者,你也应该预期在找到一个优秀的人之前要面试很多不符合你标准的人。相反,如果你犯了一个严重的错误,比如因为一些愚蠢的理由筛选掉本可能成为异常值的候选人,你很难注意到你在这样做,因为你永远无法观察到雇佣他们的反事实情况。
As a result, often the best you have to go on is your first-principles reasoning: does it seem like the things you’re filtering on are tightly correlated with actual outlier-hood? Are you discarding samples for silly reasons?
因此,通常你能依靠的最好方法是基本原理推理:你所过滤的东西似乎与实际的异常性紧密相关吗?你是否因为愚蠢的理由丢弃样本?
To have a working process for sampling from a heavy-tailed distribution, you need to solve two problems:
- A good way of evaluating whether a sample is an outlier
- A good way of drawing samples
要有一个从重尾分布中取样的有效过程,你需要解决两个问题:
- 一个评估样本是否为异常值的好方法
- 一个抽取样本的好方法
Solving the first problem is pretty idiosyncratic to the domain you’re operating in, and can be quite hard, although the suggestion above of asking friends/colleagues what outliers looked like to them (and especially what outliers looked like during the evaluation phase, e.g. how did their top hires perform in interviews), seems like it could be generally useful. Other than that, this just requires a bunch of hard domain-specific thinking.
解决第一个问题在很大程度上取决于你所处的领域,可能相当困难,尽管上面提到的建议——询问朋友/同事他们眼中的异常值是什么样子(特别是在评估阶段异常值是什么样子,例如他们最优秀的雇员在面试中表现如何)——似乎普遍有用。除此之外,这只需要大量艰难的领域特定思考。
If you do have a fast and accurate way of evaluating a sample, then it becomes much easier to tell how well your sampling strategy is working. You can iterate on different sampling strategies and see whether the candidates coming through seem better or worse. In this case, what matters most is going through samples quickly, so that you can iterate quickly.
如果你确实有一种快速准确的方法来评估样本,那么就更容易判断你的取样策略效果如何。你可以在不同的取样策略上迭代,看看通过的候选者是否看起来更好或更差。在这种情况下,最重要的是快速处理样本,这样你就可以快速迭代。
Dan Luu, who works on performance optimization at Twitter and discovered several opportunities with outlier impact, noted that this is one area where it’s very easy to evaluate whether a project idea is an outlier. Because the things you care about are relatively easy to measure, you can often make a quick back-of-the-envelope calculation and get a good estimate of how much money your idea will save. This makes it possible to go through a lot of ideas quickly.
在 Twitter 从事性能优化工作并发现了几个具有异常影响的机会的 Dan Luu 指出,这是一个很容易评估项目想法是否为异常值的领域。因为你关心的事情相对容易测量,你通常可以快速进行粗略计算,并得到你的想法能节省多少钱的良好估计。这使得快速浏览大量想法成为可能。
For another example, blog posts have a fast feedback mechanism, which is how much engagement (sharing/commenting/social media likes/reading) they get. Because of this, once I committed to writing once a week, I learned a lot very quickly about what types of blog posts would resonate with people, and got a lot better at deciding which blog post ideas to invest in writing. For instance, I noticed that people consistently found my posts on technical topics much less interesting than my general-interest posts, even though most of my readership appeared to be software engineers, so I deprioritized writing technical posts.
另一个例子是,博客文章有一个快速的反馈机制,即它们获得多少参与度(分享/评论/社交媒体点赞/阅读)。因此,一旦我承诺每周写一篇,我很快就学到了很多关于什么类型的博客文章会引起人们共鸣的知识,并在决定投资写哪些博客文章想法方面变得更好。例如,我注意到人们一直觉得我关于技术主题的文章比我的一般兴趣文章要无趣得多,尽管我的大多数读者似乎是软件工程师,所以我降低了写技术文章的优先级。
For blog posts, this strategy has an obvious potential pitfall: many writers who try to optimize for engagement end up making bad trade-offs (in my opinion) against other values—for example, they’ll use clickbait headlines, write hyperbolically without caveats, or deliberately try to provoke controversy. These work to increase short-term engagement, but writers who lean on clickbait, hyperbole or controversy are less likely to write pieces with long-lasting value. Because of traps like this, if you’re working with a feedback mechanism like blog post engagement that’s only a proxy for what you care about, it’s important to be aware of the limitations of that proxy to avoid falling victim to Goodhart’s Law.
对于博客文章,这种策略有一个明显的潜在陷阱:许多试图优化参与度的作者最终会做出(在我看来)与其他价值相悖的糟糕权衡——例如,他们会使用标题党,不加限定地夸张写作,或故意试图引发争议。这些做法能增加短期参与度,但依赖标题党、夸张或争议的作者不太可能写出具有长期价值的文章。因为有这样的陷阱,如果你使用的反馈机制(如博客文章参与度)只是你所关心的事物的代理,重要的是要意识到该代理的局限性,以避免成为古德哈特定律的受害者。
So what does a good process for searching for outliers look like?
那么,一个寻找异常值的好过程应该是什么样子的呢?
-
Take lots of shots on goal. The more samples you have, the more likely you’ll find an outlier.
-
多多尝试。你的样本越多,找到异常值的可能性就越大。
-
Know what to look for: try to figure out how good of an outcome is possible, so you know when to stop.
-
知道要寻找什么:试着弄清楚可能的结果有多好,这样你就知道什么时候该停止。
-
Find ways to evaluate candidates that are well-correlated with what you care about. Filter for “maybe amazing,” not “probably good.”
-
找到与你关心的事物高度相关的评估候选者的方法。筛选”可能惊人”的,而不是”可能不错”的。
-
When possible, try to sample and evaluate candidates quickly, so that you can iterate on your sampling process more quickly.
-
如果可能的话,尝试快速取样和评估候选者,这样你就可以更快地迭代你的取样过程。
-
Don’t get discouraged when you do the same thing over and over again and it mostly doesn’t work!
-
当你一遍又一遍地做同样的事情,而且大多数时候都不起作用时,不要灰心!