作者:Roman Leventov
Evergreen notes don’t reflect the mental maps of one’s mind
常青笔记并不反映一个人思维中的心智地图
I’ve created more than a thousand evergreen notes in about two years. This has been very useful in my learning and exploration, without a doubt.
我在大约两年内创建了超过一千条常青笔记。毫无疑问,这对我的学习和探索非常有用。
However, I don’t feel that the practice of taking evergreen notes significantly improved my mental ability to “connect the dots”:
然而,我并不觉得做常青笔记的实践显著提高了我在心智上”连接各点”的能力:
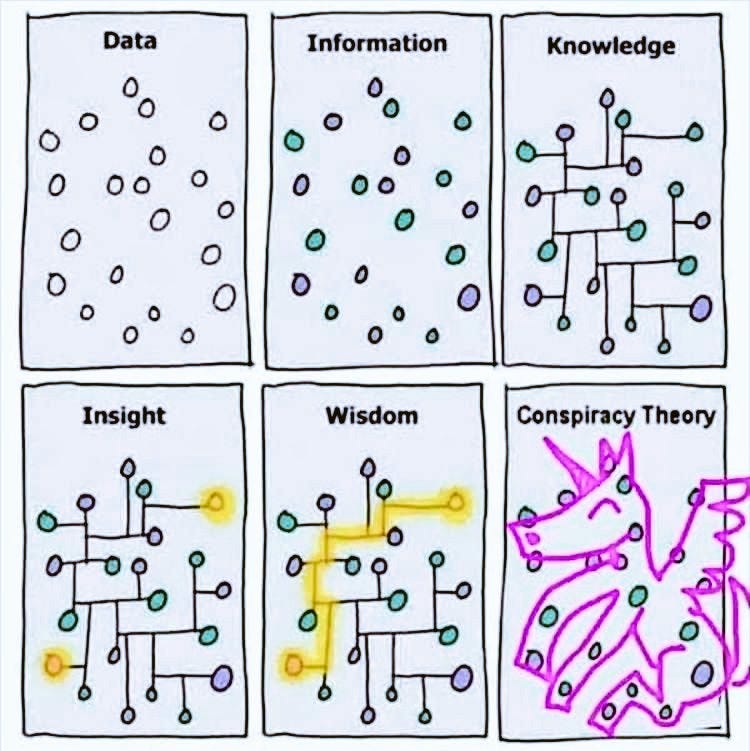
After taking an evergreen note, the usual practice is to think what already existing notes are related to the new note, and link them. I often struggle to recall more than a single related note. However, through that first link, I can explore the “link closure” and often find many more related notes.
在做一条常青笔记后,通常的做法是思考已有的哪些笔记与这条新笔记相关,并将它们链接起来。我经常难以回忆起超过一条相关笔记。然而,通过那第一条链接,我可以探索”链接闭包”,并经常找到更多相关笔记。
I regularly create a note and then through related links, I discover that almost exactly the same note already exists. I completely forget about it when I create a new note.
我经常创建一条笔记,然后通过相关链接,我发现几乎完全相同的笔记已经存在。当我创建新笔记时,我完全忘记了它。
Unfortunately, I don’t have statistics of the graph of my notes, but I’d expect the average number of links to be 6 and the median is 3. For me personally, this graph is a really valuable body of information and links. I’m often amused to explore it as if it was not me who wrote it.
不幸的是,我没有我的笔记图谱的统计数据,但我预计平均链接数为6,中位数为3。对我个人而言,这个图谱是一个非常有价值的信息和链接体。我经常乐于探索它,就好像不是我写的一样。
These observations make me think that I create an interesting garden of evergreen notes which is, however, weakly related to the mental maps of concepts , or reference frames as Jeff Hawkins calls them in A Thousand Brains . In other words, evergreen notes don’t fulfil the role of gardening and shaping my mental maps, and thus don’t improve my “bare” thinking (thinking that I can do without consulting to my web of evergreen notes.
这些观察使我认为,我创造了一个有趣的常青笔记花园,但它与概念的心智地图关系却很弱,或者用 Jeff Hawkins 在《千脑理论》中所称的参考框架。换句话说,常青笔记并没有起到培育和塑造我的心智地图的作用,因此也没有改善我的”裸”思考(即不查阅我的常青笔记网络就能进行的思考)。
Evergreen notes and Zettelkasten are good for “frontier thinking”, but not for learning a practice or a domain
常青笔记和 Zettelkasten 适合”前沿思考”,但不适合学习实践或领域知识
The fact that evergreen notes don’t reflect the mental maps of one’s mind (Zettelkasten notes also don’t, for that matter) is at least partially by design. Andy Matuschak writes that “notes should surprise you”:
常青笔记不反映一个人思维中的心智地图这一事实(Zettelkasten 笔记也不反映)至少部分是设计使然。Andy Matuschak 写道”笔记应该让你感到惊喜”:
If reading and writing notes doesn’t lead to surprises, what’s the point? If we just wanted to remember things, we have spaced repetition for that. If we just wanted to understand a particular idea thoroughly in some local context, we wouldn’t bother maintaining a system of notes over time.
如果阅读和写笔记不能带来惊喜,那有什么意义呢?如果我们只是想记住东西,我们有间隔重复系统可以用。如果我们只是想在某个特定背景下彻底理解一个想法,我们就不必费心维护一个长期的笔记系统了。
Quoting the page from the official Zettelkasten website:
引用 Zettelkasten 官方网站的一段话:
If you look something up in your Zettelkasten, you need to get unexpected results in order to form new thoughts. Surprise is the key ingredient here, as I pointed out in my introductory post on this topic. The links between notes make this possible since you’ll generate new ideas by following connections and exploring a part of your web of notes. The non-apparent connections are generally more beneficial to creative thinking than the obvious ones as they generate greater surprise. While your mind usually continues to work with the obvious, your Zettelkasten instead shows you the bizarre. It sparks your imagination and blows your mind as it confronts you with the unexpected.
如果你在 Zettelkasten 中查找某些内容,你需要得到意想不到的结果,以形成新的想法。正如我在这个主题的介绍文章中指出的那样,惊喜是这里的关键要素。笔记之间的链接使这成为可能,因为你会通过跟随连接并探索部分笔记网络来产生新想法。非显而易见的连接通常比明显的连接对创造性思维更有益,因为它们会产生更大的惊喜。虽然你的头脑通常会继续处理显而易见的内容,但你的 Zettelkasten 反而会向你展示奇特的内容。它激发你的想象力,让你大开眼界,因为它让你面对意想不到的事物。
It’s important to note here is that both Andy Matuschak and Niklas Luhmann use their note-taking systems for doing original research, whereas at least 80% of my notes are unoriginal and reflect ideas and concepts I learn from books and elsewhere. I use the evergreen note system for learning a practice or a domain and as my external memory. My main goals are improving and increasing my memory capacity, making thinking and recalling things faster and more reliable (not forgetting things I shouldn’t forget about).
这里需要注意的是,Andy Matuschak 和 Niklas Luhmann 都是将他们的笔记系统用于原创研究,而我至少 80% 的笔记都是非原创的,反映了我从书籍和其他地方学到的想法和概念。我使用常青笔记系统来学习实践或领域知识,并作为我的外部记忆。我的主要目标是提高和增加我的记忆容量,使思考和回忆事物变得更快、更可靠(不忘记我不应该忘记的事情)。
Therefore, it seems to me that while evergreen notes and Zettelkasten are good systems for doing original research or “frontier thinking”, these note-taking systems are not optimal for training one’s mind in fluent and reliable thinking in terms of a certain (professional) practice (for example, deliberating about security threats when considering certain IT solutions: a practice of security engineering) or learning the existing body of knowledge in a certain domain (for example, quantum computing).
因此,在我看来,虽然常青笔记和 Zettelkasten 是进行原创研究或”前沿思考”的好系统,但这些笔记系统并不适合训练一个人在某个(专业)实践方面进行流畅可靠的思考(例如,在考虑某些 IT 解决方案时对安全威胁进行深思熟虑:一种安全工程实践)或学习某个领域的现有知识体系(例如,量子计算)。
The current state-of-the-art idea for a tool that helps one to learn a new practice or a domain is a mnemonic medium, a text which embeds a spaced repetition memory system.
目前最先进的帮助人们学习新实践或领域的工具理念是助记媒介,即嵌入了间隔重复记忆系统的文本。
Below in this post, I propose an idea of a new tool for thought, a development of the idea of a spaced repetition system that leverages the preliminary insights about the topology of human memory and the nature of thinking from Jeff Hawkins’s “the thousand brains” theory.
在这篇文章的后面,我提出了一个新的思考工具的想法,这是对间隔重复系统理念的发展,利用了 Jeff Hawkins 的”千脑理论”对人类记忆拓扑结构和思维本质的初步洞见。
The actual structure of my evergreen notes: it’s a mess
我的常青笔记的实际结构:一团糟
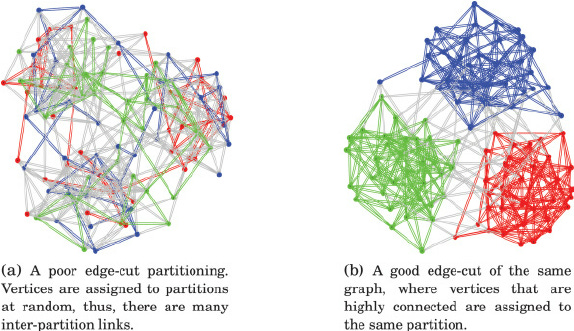
I use Notion for my evergreen notes so I cannot explore the graph of notes visually (Notion doesn’t support this feature yet), but I think that the graph resembles a quite random (no structure) and has very uneven density. There are many cliques of 5-10 notes that are almost fully interconnected. There are larger clusters, comprising several to a dozen such cliques. And there is also a big portion of notes that have only one or two links. On the other hand, there are many notes that have more than ten links.
我使用 Notion 来做常青笔记,所以我无法直观地探索笔记的图谱(Notion 还不支持这个功能),但我认为这个图谱看起来相当随机(没有结构),密度非常不均匀。有许多由5-10条笔记组成的小团体,它们几乎完全互相连接。还有一些更大的集群,包含几个到十几个这样的小团体。同时也有很大一部分笔记只有一两个链接。另一方面,还有许多笔记有超过十个链接。
This is a rough illustration of how the actual web of my evergreen notes should look (I think):
这是我认为我的常青笔记实际网络应该看起来的粗略示意图:
Andy Matuschak writes that evergreen notes should be concept-oriented. However, in practice, I see that both my and Matuschak’s notes gravitate towards the following four types of notes (examples are from my notes and from Matuschak’s):
Andy Matuschak 写道,常青笔记应该是面向概念的。然而,在实践中,我发现我和 Matuschak 的笔记都倾向于以下四种类型(例子来自我的笔记和 Matuschak 的笔记):
- Concept-oriented notes: Loss of lithium inventory, Evergreen notes.
- “Statement” notes: Electrode voltage curves are steeper when the electrode has little lithium, Most people take only transient notes.
- Imperative notes: BMS should use the remaining capacity estimate to narrow down the battery’s charge and discharge voltage limits, Evergreen notes should be densely linked
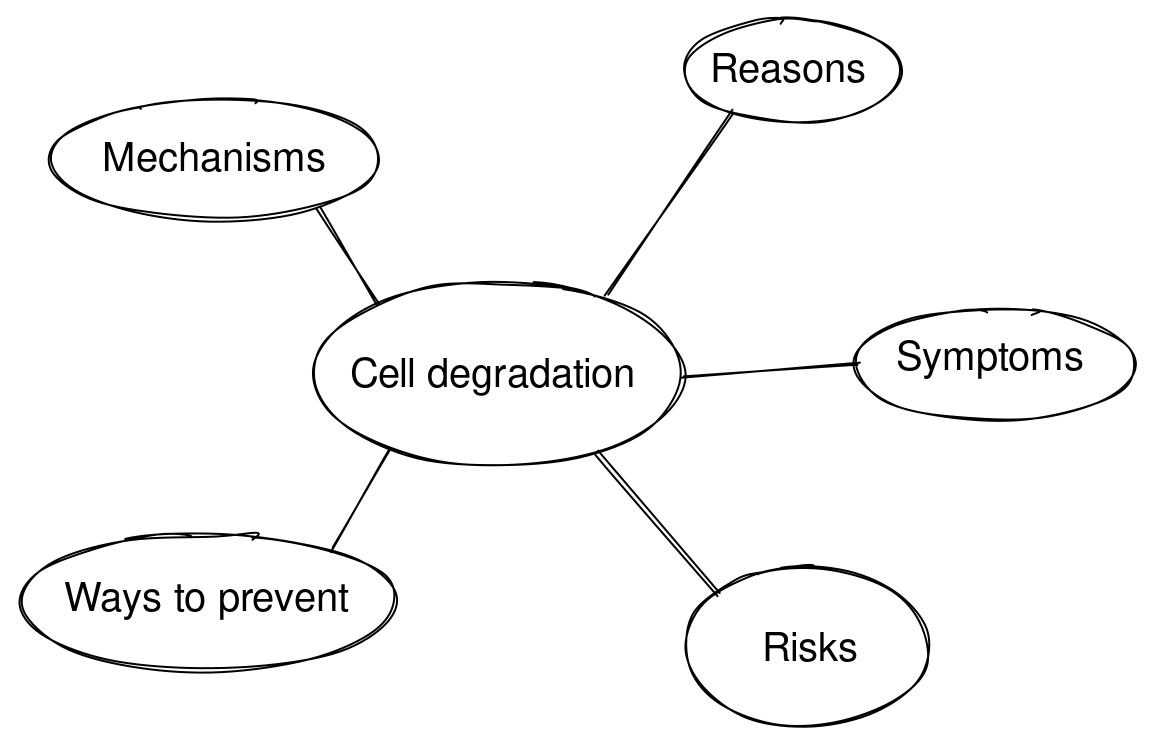
- List/“outline” notes: Positive feedback loops of cell degradation, Similarities and differences between evergreen note-writing and Zettelkasten.
- 面向概念的笔记:锂库存损失,常青笔记。
- “陈述”笔记:当电极中锂含量较少时,电极电压曲线更陡峭,大多数人只做临时笔记。
- 祈使笔记:BMS 应该使用剩余容量估计来缩小电池的充放电电压限制,常青笔记应该密集链接。
- 列表/”大纲”笔记:电池退化的正反馈循环,常青笔记写作和 Zettelkasten 之间的异同。
See Matuschak’s Taxonomy of note types.
参见 Matuschak 的笔记类型分类。
My evergreen notes (and, evidently, Matuschak’s) are not ontologically structured: a typical note with a lot of links, e. g. Lithium plating (currently has 15 links) has a lot of links with all sorts of ontological relationships to the concept note:
我的常青笔记(显然,Matuschak 的也是)在本体上并没有结构化:一个典型的有很多链接的笔记,例如锂沉积(目前有15个链接),与概念笔记有各种本体关系的链接:
- Lithium plating → Cell capacity fade: caused-by
- Lithium plating → Cell degradation: mechanism-of (transitively via Cell capacity fade)
- Lithium plating → SEI layer on anode: appear/happens-beneath (spatial relationship)
- Lithium plating → Anode overhang decreases the risk of Lithium plating: no relationship because the linked note is not concept-oriented. If there was a concept-oriented note “Anode overhang” (there is no), the relationship would be risk-reduced-by . If there was additionally a separate page “Risk of Lithium plating”, the relationship would be simply reduced-by .
- 锂沉积 → 电池容量衰减:由…引起
- 锂沉积 → 电池退化:…的机制(通过电池容量衰减间接关联)
- 锂沉积 → 阳极上的 SEI 层:出现/发生在…之下(空间关系)
- 锂沉积 → 阳极悬空减少锂沉积的风险:没有关系,因为链接的笔记不是面向概念的。如果有一个面向概念的”阳极悬空”笔记(实际上没有),关系就会是风险被…减少。如果还有一个单独的”锂沉积风险”页面,关系就会简单地是被…减少。
Mental reference frames of concepts have at most seven “features”?
概念的心智参考框架最多有七个”特征”?
Jeff Hawkins writes in A Thousand Brains :
Each cortical column can learn models (maps) of complete objects. Objects are defined by sets of observed features in the upper layer of a cortical column associated with a set of locations of/on the object (lower layer of neurons). If you know the feature, you can determine a location. If you know the location, you can predict the feature. “Features” are actually links to other reference frames, so it’s reference frames all the way down. Neocortex used hierarchy to assemble objects into more complex objects. Each cortical column can learn hundreds of models. Reference frames are used to model everything we know, not just physical objects. Thinking is moving between adjacent locations in a reference frame. All knowledge is stored at locations in reference frames. Attention plays essential role in how the brain learns models . All objects in attention are constantly added to models, either temporary or not.
Jeff Hawkins 在《千脑理论》中写道:
每个皮层柱都可以学习完整物体的模型(地图)。
物体由皮层柱上层观察到的一组特征定义,这些特征与物体上/的一组位置(神经元下层)相关联。如果你知道特征,就可以确定位置。如果你知道位置,就可以预测特征。
“特征”实际上是指向其他参考框架的链接,所以一直到底都是参考框架。新皮层使用层级结构将物体组装成更复杂的物体。
每个皮层柱可以学习数百个模型。
参考框架用于模拟我们所知道的一切,不仅仅是物理对象。思考就是在参考框架中相邻位置之间移动。所有知识都存储在参考框架的位置中。
注意力在大脑学习模型的过程中起着至关重要的作用。所有注意力中的对象都不断被添加到模型中,无论是临时的还是永久的。
Note that this last quote implies (I think Hawkins also points this out more explicitly at some point) that “current working memory” is a temporary reference frame .
注意,这最后一句话暗示(我认为 Hawkins 在某处也更明确地指出了这一点)“当前工作记忆”是一个临时的参考框架。
Hawkins’s ideas together with the idea that people can only hold about seven objects in working memory lead me to a speculative conclusion that reference frames of abstract objects (concepts) should look like stars of at most seven points . Some examples:
Hawkins 的想法加上人们在工作记忆中只能保持大约七个对象的观点,使我得出一个推测性结论:抽象对象(概念)的参考框架应该看起来像最多七个点的星形。一些例子:
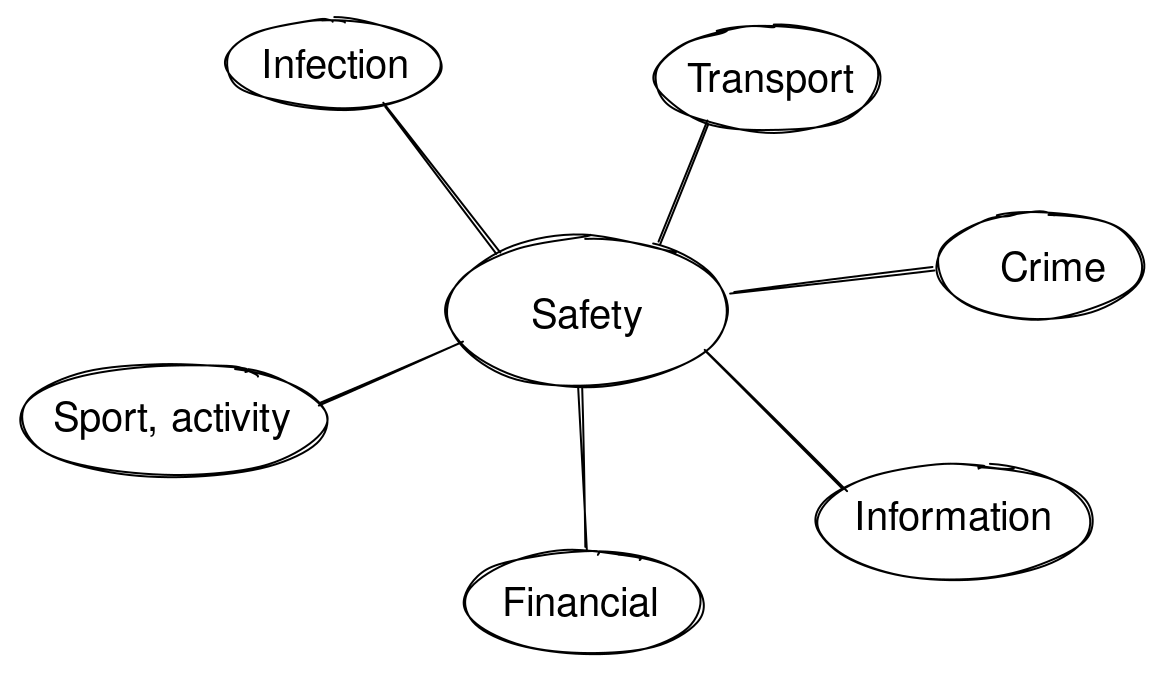
In my mental model/mental map/reference frame of “aspects/types of safety”, there are no “animals”. If I lived in the Amazonian jungle, this map would probably include “animals”, “insects”, “river”, “food”, and “neighbouring tribe”, i. e. would be completely different.
在我的”安全方面/类型”的心智模型/心智地图/参考框架中,没有”动物”。如果我生活在亚马逊丛林,这个地图可能会包括”动物”、“昆虫”、“河流”、“食物”和”邻近部落”,也就是说会完全不同。
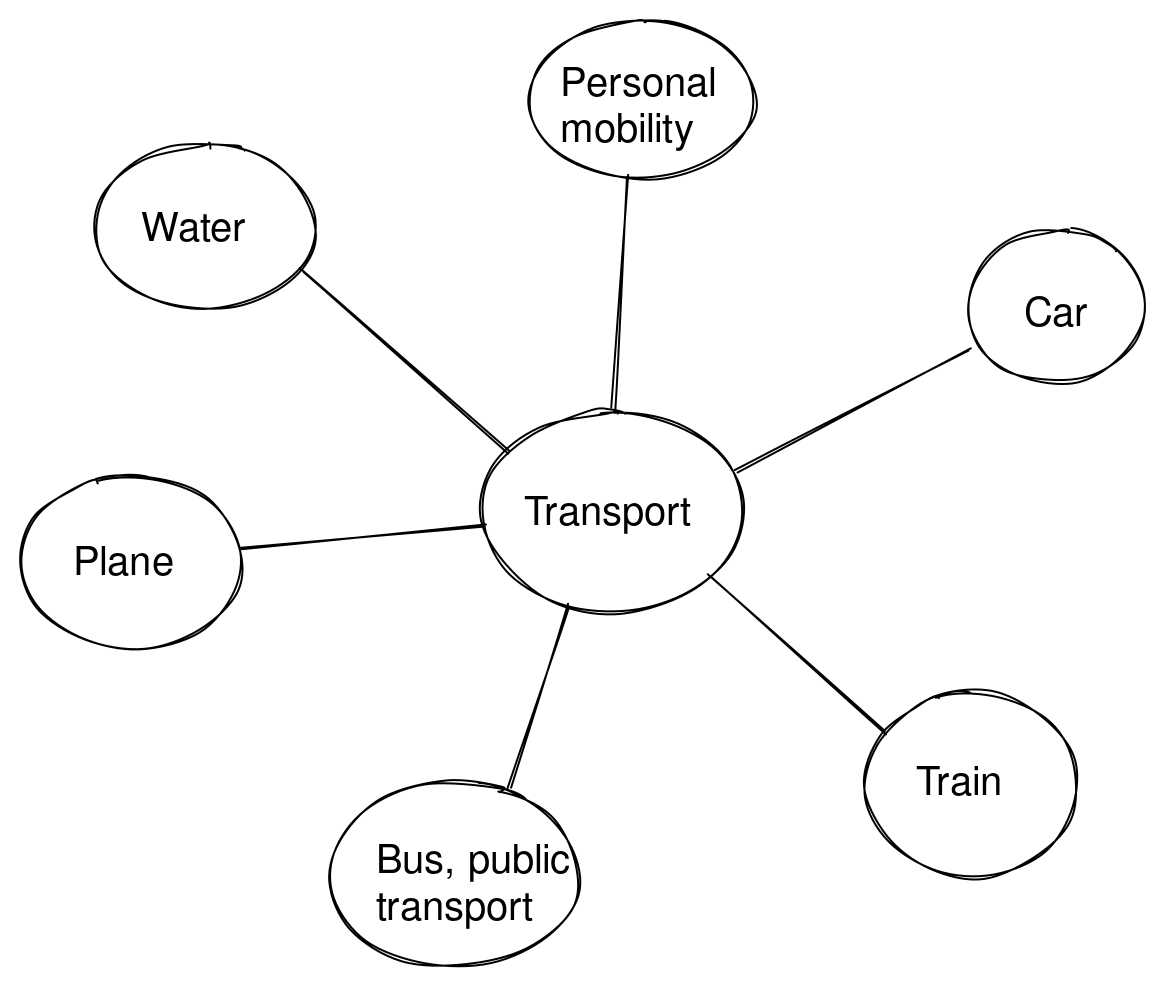
“Rocket” or “hyperloop” are not featured on my reference frame of the means of transport, but probably are present on the equivalent reference frame in Elon Musk’s mind.
“火箭”或”超级高铁”并不出现在我的交通工具参考框架中,但可能存在于 Elon Musk 头脑中的等效参考框架中。
I think that I feel that reference frames with more than seven concepts don’t exist in my mind. For example, the “software quality” is not a reference frame in my mind, I cannot navigate it, I cannot extract its features easily from my memory, despite I’ve once spent several weeks thinking almost exclusively about this topic, and documented it on Wikiversity. To talk and think about software quality, I need to refer to some notes, wiki pages, and diagrams constantly.
我认为我感觉到在我的头脑中不存在超过七个概念的参考框架。例如,“软件质量”在我的头脑中不是一个参考框架,我无法导航它,无法轻易从记忆中提取其特征,尽管我曾经花了几周时间几乎专门思考这个主题,并在维基大学上记录了它。要谈论和思考软件质量,我需要不断参考一些笔记、维基页面和图表。
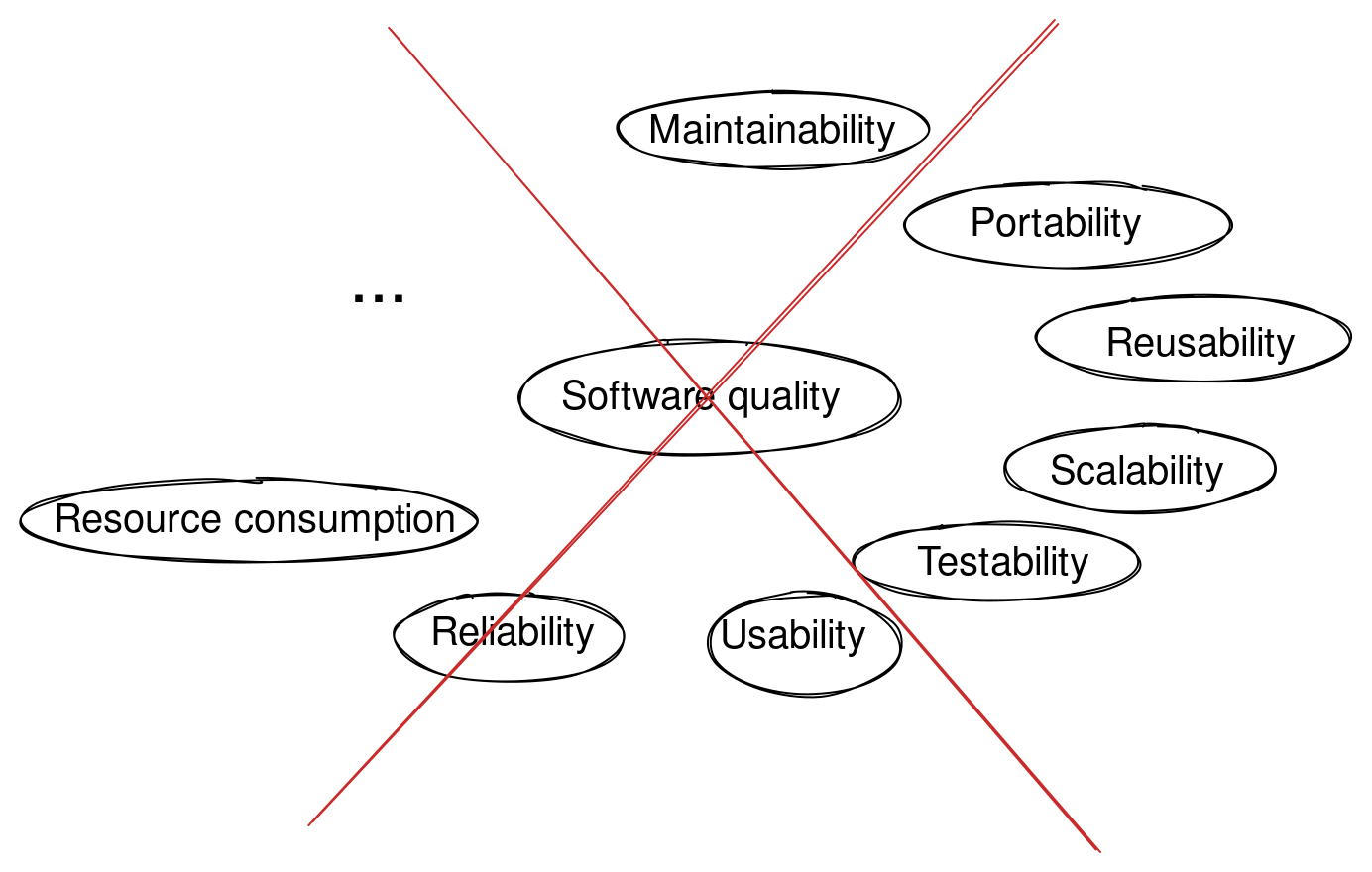
Of course, the knowledge about different software qualities is stored somehow in some reference frames in my mind because if I think long and hard, I can extract, perhaps, 15-20 qualities from my memory. But there is probably some implicit second hierarchy of concepts between the concept “software quality” and the actual qualities, or, more likely, some mess of “proto-”, “fuzzy” frames. Mental navigation in such a landscape is energetically hard, it is “real thinking”. The mental navigation in crisper, simpler frames of at most seven features is effortless, “automatic”.
当然,关于不同软件质量的知识以某种方式存储在我头脑中的某些参考框架中,因为如果我长时间深入思考,也许可以从记忆中提取出15-20个质量。但是在”软件质量”概念和实际质量之间可能存在一些隐含的第二层概念层级,或者更可能是一些”原型”、“模糊”框架的混乱。在这样的景观中进行心智导航在能量上是困难的,这是”真正的思考”。在最多七个特征的更清晰、更简单的框架中进行心智导航是毫不费力的,“自动的”。
The first implication of this conclusion is that overly connected evergreen notes don’t reflect actual reference frames in my mind and therefore don’t serve the mind in “mental navigation”, recall, solution finding, etc.
这个结论的第一个含义是,过度连接的常青笔记并不反映我头脑中的实际参考框架,因此不能在”心智导航”、回忆、寻找解决方案等方面为头脑服务。
The second implication is the new way to look at the famous “two-pizza team” rule. Traditionally, the team size of 8 is justified by the growing number of communications. But maybe people cannot place more than 7 colleagues well on their “team” reference frame?
第二个含义是看待著名的”两个披萨团队”规则的新方式。传统上,8人的团队规模是由不断增加的沟通数量来证明的。但也许人们无法在他们的”团队”参考框架中很好地容纳超过7个同事?
There are also powerful implications related to systems thinking which I cover below in this post.
还有一些与系统思维相关的强大含义,我将在这篇文章后面讨论。
Hierarchical visual/spatial reference frames are also limited to 7-9 features on a single level of the hierarchy?
分层的视觉/空间参考框架在单个层级上也限制在7-9个特征?
I suspect that even visual reference frames may not contain much more than 7 or 9 features. They all seem to be hierarchical. For example, all countries are not the direct features on the “world” reference frame. Instead, the first level is continents/parts of the world: North America, South America, Europe, Asia, Africa, Australia/Oceania. Then, within Europe, there are Scandinavia, Romanic-speaking Europe, Central Europe, Balkans, Eastern Europe. (This is my best attempt to reflect on my own mental map of Europe, in geographical/visual ontological dimension. It’s admittedly inconsistent because I also want to extract Iberia and the British Isles. Probably most of our mental models are slightly “fuzzy”, inconsistent. In the aspects of thinking where the speed and quality of thought matter, we should probably work on making them more consistent!) Then, within each sub-region, there are specific countries.
我怀疑即使是视觉参考框架也可能不会包含超过7或9个特征。它们似乎都是分层的。例如,所有国家并不是”世界”参考框架上的直接特征。相反,第一层是大陆/世界的部分:北美洲、南美洲、欧洲、亚洲、非洲、澳大利亚/大洋洲。然后,在欧洲内部,有斯堪的纳维亚、罗曼语系欧洲、中欧、巴尔干半岛、东欧。(这是我尝试反映自己对欧洲的心智地图,在地理/视觉本体维度上。诚然这是不一致的,因为我还想提取伊比利亚半岛和不列颠群岛。可能我们大多数的心智模型都有点”模糊”、不一致。在思考的速度和质量很重要的方面,我们可能应该努力使它们更加一致!)然后,在每个次级区域内,有具体的国家。
In another visual/spatial reference frame, my room, there are areas “close to bed”, “close to the table”, “close to the window”, “close to the wardrobe”.
在另一个视觉/空间参考框架中,我的房间,有”靠近床”、“靠近桌子”、“靠近窗户”、“靠近衣柜”等区域。
Perhaps, one of the reasons why the mind can think visually/spatially quicker than abstractly and remember more things is that the mind doesn’t need to switch the type of relationship when it moves through the hierarchy: it remains spatially-part-of/located-within/located-near . Per Hawkins, this constitutes a single reference frame(?), and thinking is the very act of movement within this frame. On the other hand, abstract thinking seems to sometimes cross a boundary of two reference frames. For example: Anode overhang decreases the risk of Lithium plating: “Lithium plating” → (object-of-attention/alpha) “Risks of Lithium plating” → (reduced-by) “Anode overhang”, two different reference frames are involved in this idea/thought.
也许,头脑能够比抽象思考更快地进行视觉/空间思考并记住更多事物的原因之一是,当头脑在层级中移动时不需要切换关系类型:它始终保持空间部分/位于内部/位于附近。根据 Hawkins 的说法,这构成了一个单一的参考框架(?),思考就是在这个框架内移动的行为。另一方面,抽象思考似乎有时会跨越两个参考框架的边界。例如:阳极悬空减少锂沉积的风险:“锂沉积” → (注意对象/alpha)“锂沉积的风险” → (被…减少)“阳极悬空”,这个想法/思考涉及两个不同的参考框架。
Features in the reference frames have the same type of relationship with the concept
参考框架中的特征与概念具有相同类型的关系
Another difference between the actual reference frames in my mind and evergreen notes that I create is that reference frames are approximately ontologically consistent: all features in a “star frame” are connected with the concept with approximately the same ontological relationship.
我头脑中的实际参考框架与我创建的常青笔记之间的另一个区别是,参考框架在本体上大致一致:“星形框架”中的所有特征都以大致相同的本体关系与概念相连。
This seems to be another reason why evergreen notes don’t reflect the actual structure of mental maps and don’t seem to increase the speed of bare thinking. Most of my evergreen notes are either statements (what is) or imperative notes (what should be). Both these types of notes represent compete thoughts, or “walks”/“pathways” across some implicit reference frames. Often these notes are linked to each other with a relationship “related-to ”, which is a relationship between thoughts/ideas, not concepts. My mind doesn’t seem to build a lot (if any) of reference frames in the related-to dimension. This is why, I think, I keep having a hard time recalling things that I wrote in my evergreen notes.
这似乎是常青笔记不能反映心智地图的实际结构,也不能提高纯粹思考速度的另一个原因。我的大多数常青笔记要么是陈述(是什么),要么是祈使笔记(应该是什么)。这两种类型的笔记都代表完整的思想,或者是跨越一些隐含参考框架的”行走”/“路径”。这些笔记经常以”相关于”的关系相互链接,这是思想/想法之间的关系,而不是概念之间的关系。我的头脑似乎并没有在”相关于”维度上建立很多(如果有的话)参考框架。我认为,这就是为什么我一直难以回忆起我在常青笔记中写的东西。
Explaining the power of systems thinking practices using reference frames
用参考框架解释系统思维实践的力量
Anatoly Levenchuk’s book Systems Thinking (available as a course in English here, as a book in Russian here) has many powerful ideas. Some of them, as I now think, can be explained nicely with the speculative insights about reference frames in people’s minds (which I covered above).
Anatoly Levenchuk 的《系统思维》一书(英文课程版本在这里,俄文书籍版本在这里)有许多强大的想法。我现在认为,其中一些可以用关于人们头脑中参考框架的推测性见解(我在上面已经讨论过)很好地解释。
Extracting system levels is a mind-gardening practice
提取系统层级是一种心智培育实践
A systems thinker should carefully “extract”/separate system levels among different dimensions: functional, constructive, spatial, economic, and more.
系统思考者应该仔细地”提取”/分离不同维度的系统层级:功能、构造、空间、经济等等。
A nice property of the resulting system breakdowns is that they rarely have more than seven components/sub-systems. For example, here’s a possible functional breakdown of a car:
由此产生的系统分解的一个好特性是,它们很少有超过七个组件/子系统。例如,这里是汽车可能的功能分解:
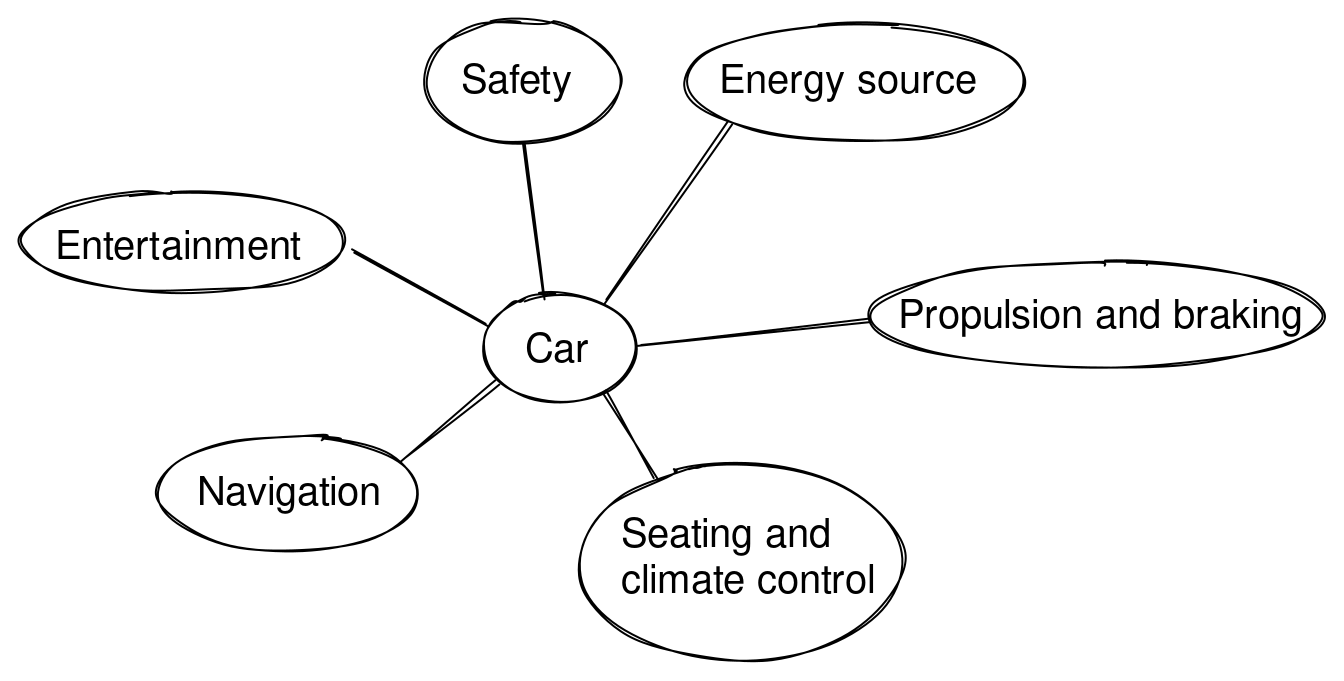
The functional sub-systems of “Seating and climate control” system could be “windows”, “roof/doors”, “seats”, “climate control”.
“座椅和气候控制”系统的功能子系统可能是”窗户”、“车顶/车门”、“座椅”、“气候控制”。
In just about any system and any kind of system breakdown, it should be a rare situation when there are more than seven functional/constructive/spatial/cost/etc. components in a system and no intermediate/hierarchical system levels could be plausibly extracted.
在几乎任何系统和任何类型的系统分解中,系统中有超过七个功能/构造/空间/成本等组件,而且无法合理提取中间/层级系统级别的情况应该是罕见的。
The punch line is, of course, that these breakdowns with seven or fewer features can be directly represented in the minds of the people who work with the system as a single reference frame. This makes thinking about the system more economical and predictable : people would be less likely to forget about components even if they don’t constantly refer to diagrams and text.
当然,重点是这些具有七个或更少特征的分解可以直接在使用该系统的人的头脑中表示为单个参考框架。这使得对系统的思考更加经济和可预测:即使人们不经常参考图表和文本,也不太可能忘记组件。
Communication should become more reliable with shared reference frames
共享参考框架应该使沟通变得更可靠
Levenchuk stresses in the book that system breakdowns should be shared/agreed upon/collaboratively created by all people who work on the system. And while it’s a truism that alignment reduces the need for micro-coordination in projects, the additional benefit of aligning on system breakdowns is that if team members and stakeholders all internalise them as singular reference frames in their minds, communication becomes even more efficient and losses decrease. Communication without alignment on system breakdowns looks like this:
Levenchuk 在书中强调,系统分解应该由所有在系统上工作的人共享/达成一致/协作创建。虽然一致性减少了项目中微观协调的需求是一个老生常谈,但在系统分解上达成一致的额外好处是,如果团队成员和利益相关者都将它们内化为他们头脑中的单一参考框架,沟通会变得更加高效,损失会减少。没有在系统分解上达成一致的沟通看起来像这样:
Vague/fuzzy/idiosyncratic topology of reference frames in the mind of person A → Language (as produced by person A: phrases, speech, text) → (losses in speaking/writing/reading/hearing) → Language (as perceived by person B) → Vague/fuzzy/idiosyncratic topology of reference frames in the mind of person B.
人 A 头脑中参考框架的模糊/不清晰/特殊拓扑结构 → 语言(由人 A 产生:短语、言语、文本) → (在说/写/读/听中的损失) → 语言(被人 B 感知) → 人 B 头脑中参考框架的模糊/不清晰/特殊拓扑结构。
The problem here is that since the topology (and the set) of reference frames in the mind of person B is different from those in the mind of person A, any losses and mistakes are exacerbated. Also, in long chains of communication, person A → person B → person C, the message gets transformed because there is no shared internal “base” in the minds of these people. This is the Chinese whispers effect.
这里的问题是,由于人 B 头脑中参考框架的拓扑结构(和集合)与人 A 头脑中的不同,任何损失和错误都会被放大。此外,在长链条的沟通中,人 A → 人 B → 人 C,信息会被转变,因为这些人的头脑中没有共享的内部”基础”。这就是”传话游戏”效应。
When, on the contrary, people have similar reference frames of system breakdowns in their minds, mistakes during communication are likely contained much better: the receiver needs to “pigeonhole” the message into the same topology of reference frames as from which it originated. Mistakes in the message (remember: a message is a pathway in or across the reference frames) should often be effectively “error-corrected” to the original message. Also, multi-stage communication when all people in the chain share a map of reference frames (system breakdowns) should be much more reliable: errors should not amplify as quickly as in the case when these people don’t share reference frames.
相反,当人们头脑中有相似的系统分解参考框架时,沟通过程中的错误很可能会被更好地控制:接收者需要将信息”归类”到与其起源相同的参考框架拓扑结构中。信息中的错误(记住:信息是参考框架内或跨参考框架的路径)通常应该被有效地”纠错”为原始信息。此外,当链条中的所有人都共享一个参考框架地图(系统分解)时,多阶段沟通应该更加可靠:错误不应该像这些人不共享参考框架的情况下那样快速放大。
The reference frames of project alphas
项目 alpha 的参考框架
In systems thinking terminology, alpha is “an important object of attention” (whose progress should be tracked to track the overall progress of the project or assess the health of the project). Alpha-of and sub-alpha-of are the corresponding types of ontological relationships.
在系统思维术语中,alpha 是”重要的关注对象”(应该跟踪其进展以跟踪项目的整体进展或评估项目的健康状况)。Alpha-of 和 sub-alpha-of 是相应类型的本体关系。
Seven main alphas can be extracted in almost any project (not necessarily software development project, albeit the framework of alphas (OMG Essence) was originally developed by Ivar Jacobson for software projects):
几乎任何项目中都可以提取七个主要的 alpha(不一定是软件开发项目,尽管 alpha 框架(OMG Essence)最初是由 Ivar Jacobson 为软件项目开发的):
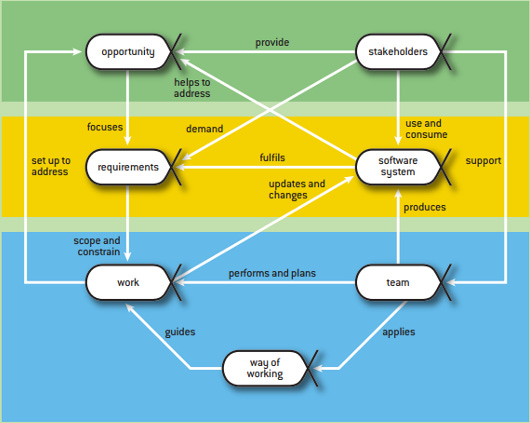
Seven alphas nicely fit in a single mental reference frame (which, again, makes thinking quicker, more economical, and more reliable):
七个 alpha 很好地适合单个心智参考框架(这再次使思考更快、更经济、更可靠):

Every project lambda has its own sub-alphas , those sub-alphas have their own sub-alphas, and so on. All these breakdowns can be mental reference frames, too.
每个项目 lambda 都有自己的 sub-alphas ,这些 sub-alphas 又有自己的 sub-alphas,以此类推。所有这些分解也可以是心智参考框架。
By the way, I don’t feel that there are “horizontal”, mesh-like connections between features in these reference frames of abstract concepts, as depicted in the picture above. At least, not in my mind. At best, there are many proto-frames with just one feature, but all these frames are weakly connected to each other and therefore don’t aid thinking (again, this is according to my reflective feeling only). It might be that I didn’t acquire the necessary mental tools/habits to track such “horizontal” relationships in the reference frames. Alternatively, I may belong to a part of the population that lacks such an ability. Finally, this might be universal for all human minds.
顺便说一下,我不觉得在这些抽象概念的参考框架中存在上图所描绘的”水平的”、网状的特征之间的连接。至少,在我的头脑中没有。充其量,有许多只有一个特征的原型框架,但所有这些框架之间的连接都很弱,因此无助于思考(再次强调,这只是根据我的反思感受)。可能是我没有获得必要的心智工具/习惯来跟踪参考框架中这种”水平”关系。或者,我可能属于缺乏这种能力的人群。最后,这可能对所有人类头脑都是普遍的。
Strengthen the intelligence by growing the repertoire of reference frame dimensions
通过增加参考框架维度的repertoire来增强智力
Although it seems to me that the number of features on a single reference frame attached to a concept is limited to seven or so, the overall density of the concept graph, and thus the speed and the quality of thinking can be improved by increasing the number of reference frames attached to every concept. As Hawkins wrote, the brain can handle this easily: a single cortical column can learn and store hundreds of reference frames. (This doesn’t imply that cortical columns responsible for abstract thinking are dedicated to a single concept each: I think Hawkins didn’t assert this in the book.)
虽然在我看来,附加到一个概念的单个参考框架上的特征数量限制在七个左右,但通过增加附加到每个概念的参考框架数量,可以提高概念图的整体密度,从而提高思考的速度和质量。正如 Hawkins 所写,大脑可以轻松处理这一点:单个皮层柱可以学习和存储数百个参考框架。(这并不意味着负责抽象思维的皮层柱每个都专门用于单个概念:我认为 Hawkins 在书中并没有这样断言。)
In Systems Thinking , Levenchuk introduces several types of relationships that people usually don’t think about: functional-part-of , constructive-part-of , spatial-part-of , cost-part-of , sub-alpha-of . Use them in system breakdowns to increase the density of the concept graph in your mind.
在《系统思维》中,Levenchuk 介绍了几种人们通常不会考虑的关系类型:functional-part-of , constructive-part-of , spatial-part-of , cost-part-of , sub-alpha-of 。在系统分解中使用它们,以增加你头脑中概念图的密度。
Systems thinkers should also deliberately seek new types of relationships relevant to a particular project (system, area of research), document them, and build system breakdowns (i. e., reference frames) using these new dimensions.
系统思考者还应该有意识地寻求与特定项目(系统、研究领域)相关的新类型关系,记录它们,并使用这些新维度构建系统分解(即参考框架)。
The idea for a new tool for thought: “mind gardener”, AI assistant that helps to build a topology of reference frames in the mind of a learner
一个新的思考工具的想法:“心智园丁”,帮助在学习者头脑中构建参考框架拓扑结构的 AI 助手
The first users would be individuals who learn some complex domain (e. g. a professional practice, or a field of science) and want to make their thinking in this domain quicker, more reliable, and more economical energetically. In other words, these are the same people who Andy Matuschak targets with mnemonic medium: the mnemonic medium should be developed in a context where people really need fluency.
第一批用户将是那些学习某些复杂领域(例如专业实践或科学领域)并希望使他们在这个领域的思考更快、更可靠、更节能的个人。换句话说,这些人就是 Andy Matuschak 用助记媒介瞄准的同一群人:助记媒介应该在人们真正需要流利度的背景下开发。
The tool helps learners to deliberately build and garden their mental maps (reference frames) in a certain domain , heavily leveraging natural language models and applying natural language inference to overcome the failure weaknesses of the earlier attempts at building such tools.
In terms of the interface, I think the tool should be like a visual graph modeller and explorer, similar to TheBrain tool, rather than a text editor. However, I think that the tool should impose two important limitations:
- Different reference frames (based on different types of relationships between the concept and features, i. e. different ontologies) should be clearly separated and, perhaps, even not appear on the same screen. TheBrain tool doesn’t separate ontologies, all connections live in the same visual space (just as the links between my evergreen notes are all similar). I think this confuses the reference frames in the learner’s mind.
- Don’t allow more than seven features in a single reference frame. A deliberate limitation, a-la Twitter’s 140-symbol limit, should ensure that the tool actually reflects the reference frames in the learner’s mind, rather than drifts towards an elaborate, explorative web of knowledge detached from the learner’s mind.
该工具帮助学习者在某个领域有意识地构建和培育他们的心智地图(参考框架),大量利用自然语言模型并应用自然语言推理来克服早期尝试构建此类工具的失败弱点。
- 不同的参考框架(基于概念和特征之间不同类型的关系,即不同的本体)应该清晰地分开,甚至可能不出现在同一个屏幕上。 TheBrain 工具不分离本体,所有连接都存在于同一个视觉空间中(就像我的常青笔记之间的链接都是相似的)。我认为这会混淆学习者头脑中的参考框架。
- 不允许在单个参考框架中超过七个特征。一个刻意的限制,类似于 Twitter 的 140 个字符限制,应该确保该工具实际反映学习者头脑中的参考框架,而不是偏离成为一个脱离学习者头脑的精细的、探索性的知识网络。
The tool should be probabilistic and leverage natural language models heavily
该工具应该是概率性的,并大量利用自然语言模型
I think a big drawback of existing ontology editors is that they are too formal and not probabilistic and imprecise enough. The concepts in the proposed tool should be nebulous by default: a concept in a tool doesn’t have a single fixed title (unlike evergreen notes, whose titles are like APIs). When a learner adds a new concept using a particular word or phrase, the tool automatically expands it into a cloud of words and terms (using a language model), and coalesces (or probabilistically attaches) the concept with already existing concepts: e. g., if the learner added “public transport” and “bus” in different reference frames, they should automatically attach to each other with some probability.
我认为现有本体编辑器的一个大缺点是它们太正式,不够概率化和不精确。提议工具中的概念应该默认是模糊的:工具中的概念没有单一固定的标题(不像常青笔记,其标题就像 API)。当学习者使用特定的词或短语添加新概念时,该工具会自动将其扩展为一组词和术语(使用语言模型),并将该概念与已有概念合并(或概率性地附加):例如,如果学习者在不同的参考框架中添加了”公共交通”和”公共汽车”,它们应该以某种概率自动相互附加。
The tool should find a very fine balance between the relative formalism/strictness of ontologies (every reference frame should be ontologically consistent) and the fuzziness of associations, nebulosity of concepts . (Here, I adapt Levenchuk’s idea with regard to why formal architecture modelling tools lose to more informal tools such as coda.io.)
该工具应该在本体的相对形式主义/严格性(每个参考框架应该在本体上保持一致)和关联的模糊性、概念的不确定性之间找到一个非常微妙的平衡。(在这里,我借鉴了 Levenchuk 关于为什么正式的架构建模工具输给了像 coda.io 这样更非正式的工具的想法。)
The tool could also use the language model to automatically choose the phrase or the word which is most appropriate to denote the concept in a particular reference frame view.
该工具还可以使用语言模型自动选择最适合在特定参考框架视图中表示概念的短语或词语。
The tools could also leverage the language model (primed with the books and other written materials on the domain being studied, e. g., a web of evergreen notes) to suggest to the learner new nodes in reference frames:
这些工具还可以利用语言模型(以所学领域的书籍和其他书面材料为基础,例如常青笔记网络)向学习者建议参考框架中的新节点:
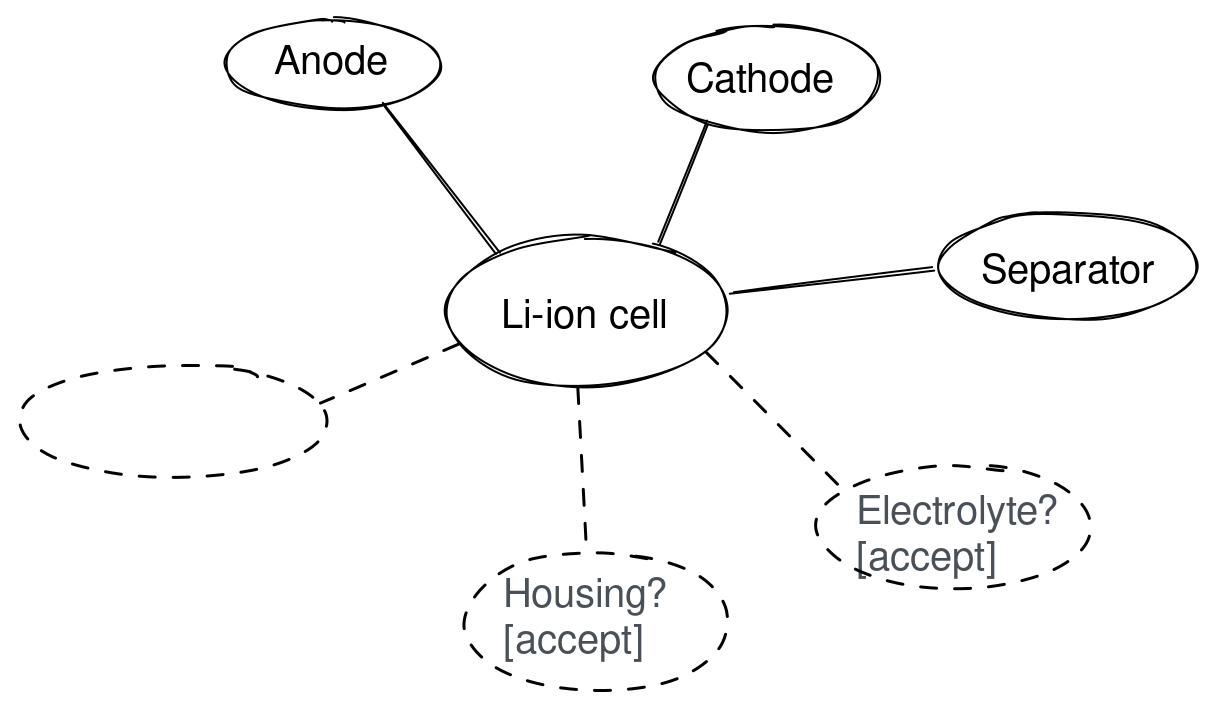
When the type of relationship is not explicitly specified by the learner (for example, on the reference frame above, it is not explicitly said that the relationship between “Li-ion cell” concept and the features is functional-part-of ) the tool may derive it automatically using its language model and annotate the relationships in the navigation interface.
当学习者没有明确指定关系类型时(例如,在上面的参考框架中,没有明确说明”锂离子电池”概念与特征之间的关系是 functional-part-of ),该工具可以使用其语言模型自动推导出关系,并在导航界面中注释这些关系。
The tool may also suggest to the learner to add new reference frames to existing concepts: “You have added a functional breakdown of a Li-ion cell, would you like to add constructive breakdown now?”
该工具还可以建议学习者为现有概念添加新的参考框架:“你已经添加了锂离子电池的功能分解,现在要添加构造分解吗?”
It’s perhaps not within the reach of the state-of-the-art natural language models existing today to suggest to the learner how to optimise the concept structure, extract new concepts (and perhaps even suggest new original words for these concepts, using some morphological models!), or coalesce concepts, but in five years from now, AI should definitely help human learners to improve the structure of their mental reference frames.
也许现有的最先进的自然语言模型还无法向学习者建议如何优化概念结构、提取新概念(甚至可能使用一些形态学模型为这些概念建议新的原创词!)或合并概念,但在五年后,AI 肯定应该帮助人类学习者改进他们心智参考框架的结构。
At present, the tool should at least try to make reorganising the topology of concepts as easy as possible, automate it: I think that “structure ossification” is a big issue with most existing knowledge management, spaced repetition, and note-taking systems. Perhaps, the probabilistic nature of the tool could be helpful here.
目前,该工具至少应该尝试使重组概念拓扑结构尽可能简单,自动化它:我认为”结构僵化”是大多数现有知识管理、间隔重复和笔记系统的一个大问题。也许,该工具的概率性质在这里可能会有所帮助。
Authored sets of reference frames (mental maps) in a mnemonic medium
助记媒介中的参考框架(心智地图)作者集
Many types of prompts which Andy Matuschak describes in “How to write good prompts: using spaced repetition to create understanding” elucidate different parts of conceptual reference frames: many “simple fact”, conceptual prompts, and all list prompts invite the learner to recall features of some reference frame (and procedural prompts train sequence memory, which the proposed new tool could support, too, but discussing it is out of scope of this post).
Andy Matuschak 在”如何写好提示:使用间隔重复创造理解”中描述的许多类型的提示阐明了概念参考框架的不同部分:许多”简单事实”、概念提示和所有列表提示都邀请学习者回忆某些参考框架的特征(而程序性提示训练序列记忆,提议的新工具也可以支持,但讨论它超出了本文的范围)。
Therefore, it seems that a mnemonic medium with a good set of prompts presupposes a relatively well-defined set of reference frames (in the mind of the author of the mnemonic medium), but stops short of trying to impart these reference frames to the learners more explicitly than “by example”, i. e. via prompts and spaced repetition of these prompts.
因此,似乎一个具有良好提示集的助记媒介预设了一组相对明确的参考框架(在助记媒介作者的头脑中),但没有试图比”通过示例”更明确地将这些参考框架传授给学习者,即通过提示和这些提示的间隔重复。
I don’t see a particular value in striping learners of the ability to explore the reference frames more directly, once they finished writing a mnemonic medium or a course. So, the proposed tool may be integrated with mnemonic mediums: it could be loaded with a set of reference frames which the learner should “fill in”/“unlock”, like in a computer game.
我认为,一旦学习者完成了助记媒介或课程的编写,剥夺他们更直接探索参考框架的能力并没有特别的价值。因此,提议的工具可以与助记媒介集成:它可以加载一组参考框架,学习者应该”填充”/“解锁”,就像在电脑游戏中一样。
Spaced repetition
间隔重复
Of course, the tool should include spaced repetition features to help learners to drive the reference frames into their minds, and retain these reference frames over time.
当然,该工具应该包括间隔重复功能,以帮助学习者将参考框架驱入他们的头脑,并随时间保留这些参考框架。
The tool could automatically generate conceptual, list, simple fact, and procedural prompts from the structure of reference frames and mapped concepts.
该工具可以根据参考框架和映射概念的结构自动生成概念、列表、简单事实和程序性提示。
A tool may also have another interesting type of “memory drill” which most spaced repetition systems currently don’t: find one or several “pathways” through reference frames between two concepts, e. g. Cell degradation and “Anode overhang”:
- Cell degradation → (mechanism) Lithium plating → (alpha) Risk of Lithium plating → (decreased-by) Anode overhang;
- Cell degradation → (process-in) Li-ion cell → (functional-part) Anode → (spatial-part) Anode overhang.
该工具还可能有另一种有趣的”记忆训练”类型,目前大多数间隔重复系统都没有:在两个概念之间通过参考框架找到一个或几个”路径”,例如电池退化和”阳极悬空”:
- 电池退化 → (机制) 锂沉积 → (alpha) 锂沉积风险 → (被…减少) 阳极悬空;
- 电池退化 → (过程-在) 锂离子电池 → (功能部分) 阳极 → (空间部分) 阳极悬空。
This is similar to the six degrees of Wikipedia game.
这类似于维基百科六度游戏。
The tool may analyse the pathways that the learner suggests to determine which dimensions (ontologies) the learner doesn’t use and likely forgot to inform the future spaced repetition prompts.
该工具可以分析学习者建议的路径,以确定学习者没有使用哪些维度(本体),并可能忘记告知未来的间隔重复提示。
Conclusions
Personal webs of “evergreen” notes and Zettelkasten notes are very useful for exploring new ideas and doing “frontier thinking”, but are not optimal to increase the fluency and reliability of thinking in a known domain, such as an area of research or a professional practice. This is because the structure of notes doesn’t reflect well how the knowledge is stored in the human mind.
“常青”笔记和 Zettelkasten 笔记的个人网络对于探索新想法和进行”前沿思考”非常有用,但对于提高已知领域(如研究领域或专业实践)思考的流畅性和可靠性并不是最优的。这是因为笔记的结构没有很好地反映知识在人类头脑中的存储方式。
I speculate that conceptual knowledge is stored in “reference frames” that look like a concept in the middle connected to at most seven features . The type of relationship between the concept and the features (features are other concepts) is more or less consistent within a reference frame.
我推测概念知识存储在”参考框架”中,这些框架看起来像是中间的一个概念连接到最多七个特征。概念和特征(特征是其他概念)之间的关系类型在参考框架内或多或少是一致的。
Therefore, I suggest that overly connected “notes” or concepts in a personal ontology editor are not as “good” in speeding up one’s thinking, as, for example, overly connected “hub” airports in speeding up air travel. Reference frames with more than seven features probably don’t exist or work poorly.
因此,我建议个人本体编辑器中过度连接的”笔记”或概念在加速思考方面并不像过度连接的”枢纽”机场加速空中旅行那样”好”。具有超过七个特征的参考框架可能不存在或效果不佳。
In systems thinking (creating system breakdowns) and designing one’s own reference frames for thinking in a certain domain, strive to extract concepts and breakdowns so that the “fanout order” in the topology always stays below seven. Increase the overall connectivity of your “mental map of concepts” by adding new reference frames (mapping out new ontological relationships between concepts), not by adding more features to existing reference frames.
在系统思维(创建系统分解)和设计自己的参考框架以在某个领域进行思考时,努力提取概念和分解,使拓扑结构中的”扇出顺序”始终保持在七以下。通过添加新的参考框架(绘制概念之间的新本体关系)来增加你的”概念心智地图”的整体连通性,而不是通过向现有参考框架添加更多特征。
Finally, I propose an idea for a new tool for thought, building upon the features of ontology editors and spaced repetition systems, that leverages state-of-the-art natural language models to help learners to build and “garden” the reference frame maps in their minds.
最后,我提出了一个新的思考工具的想法,在本体编辑器和间隔重复系统的特性基础上,利用最先进的自然语言模型来帮助学习者在他们的头脑中构建和”培育”参考框架地图。