卷首语
本篇文章是周刊的第一篇,今年年初也尝试过写周刊,但是在 15 期之后就没有再坚持,反思了一下,主要是 3 点原因
- 输出的内容多是对别人内容的总结,本质和 AI 总结没有缺别,缺少自己的思考和应用场景
- 信息来源太窄,又想要追求独特性,能够摘录的内容自然就少了
- 缺少反馈,发布之后没有反馈信息自然就不知道坚持的意义
所以这次的周刊,制定的三个选题标准都是和自己相关,同时也是李继刚提到的“六经注我”
此外输出的内容,也不再采用总结的形式,而是自己的感想、未来的用处、推荐的理由,不在追求内容的完备,而是“自己的想法”

Prompt
The warm glow of the sunrise bathes the scene as a classic steam train prepares to depart. Billowing clouds of steam rise above as the conductor, a silhouette against the morning light, signals the departure. This enchanting moment captures the romance of rail travel, harkening back to a bygone era when the rhythm of the tracks and the whistle of the engine were the heartbeat of travel and adventure.
内容推荐
我做了一个 AI 搜索引擎
艾逗笔这篇文章第一个感受是“技术祛魅”,AI 搜索本质上的实现步骤其实不复杂,总结起来只有三步(RAG:检索增强生成)
- 检索(Retrieve):拿用户的输入内容,调用搜索引擎 API,拿到搜索结果
- 增强(Augmented):设置提示词,把检索结果 + 提示词交给大模型处理
- 生成(Generation):大模型回答问题,标注引用来源
但是在简单的实现步骤下,实现细节却又是复杂的,比如
- 在第一步搜索阶段
- 是不是需要联网搜索,AI 是不是可以直接回答
- 去哪些网站搜索,除了 Google 的搜索结果,Wikipedia、Tiwtter 也都是很好的搜索结果来源
- 除了文字,图片、视频也是信息来源
- 输入的内容可以使用 AI 优化,获取更准确的搜索结果
- 在第二步增强阶段
- 如果对搜索结果重排(Ranking),也就是去除不重要的内容,把相关度高的内容往前排
- 如果设置提示词,让 AI 更好的对搜索结果处理
最后是作者对 AI 搜索的一些观点,整理下来作为参考
- AI 搜索引擎的第一要义是准确度
- ChatGPT自己做搜索,首先保证了问答底座模型的智能程度
- 大模型厂商自己做 AI 搜索 就一定会比第三方做的好
- 做好 AI 搜索引擎,最重要的三点是准 / 快 / 稳,即回复结果要准,响应速度要快,服务稳定性要高
- AI 搜索引擎是一个持续雕花的过程
- AI Search + Agents + Workflows 是趋势
- 我个人不是太看好垂直搜索引擎
- AI 搜索是一个巨大的市场,短时间内很难形成垄断
- AI 搜索引擎需要尽早考虑成本优化
可复制的决策
可复制决策的四个维度
- 一事一决
- 制定原则
- 提炼方法
- 构建系统
给自己的一个启发是“提炼方法”其实是在“制定原则”之上的一个维度,而自己一直都弄反了。我很习惯收集决策原则的内容,比如“可以反悔的决策,要快速决定;不可以反悔的决策,要谨慎判断”,原则是正确的,但是在实际操作时却没有太大的帮助
另一个启发是构建系统,我的理解系统是“自动化自迭代的体系”,是最节省成本的决策方式
归因
归因的 6 个阶段
- 环境:最通用的“背锅侠”,任何事情都可以归咎为环境问题
- 行为:归咎于自己不够努力,只要自己足够努力,就可以达到目标
- 能力:归咎于自己不够强,失败是因为缺少的专业技能、情商、思维方式
- 信念:归咎于即自己的原则、价值观
- 身份:即“我是什么样的人,就应该做什么样的事情”
- 精神:最高维度,即“我来到世界,要如何实现自我价值”
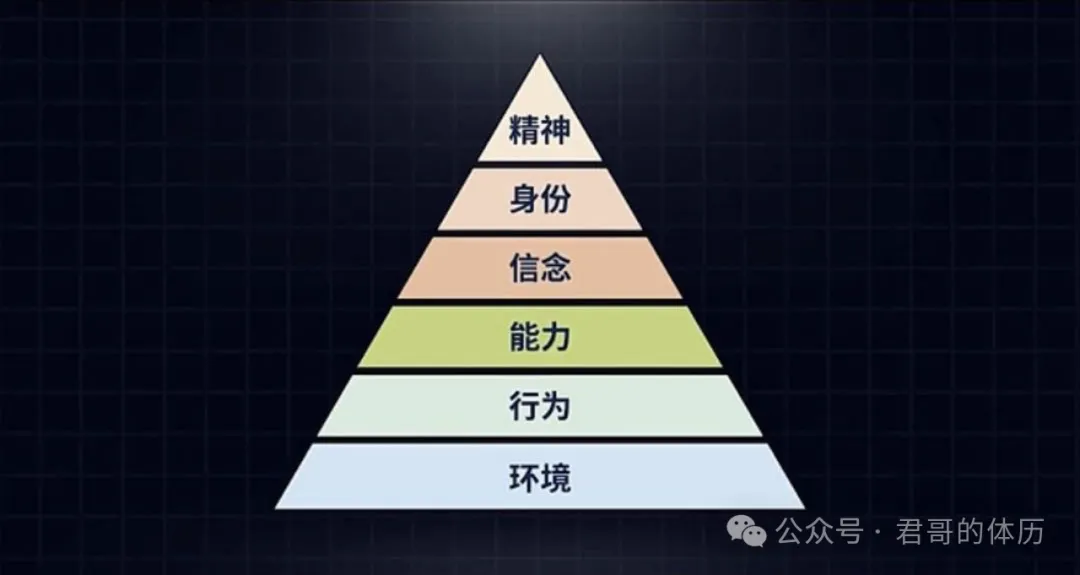
这是一个关于思考、复盘维度的模型,我经常把自己的失败归因于「环境」、「行为」和「能力」,也就是自己不够努力,因为不够努力缺少某些专业技能
- 比如自己的考研是自己不够努力
- 没有去成想去的公司是因为自己的技能点不够多
但要解决当前层面的问题,需要再上一个维度思考,从「信念」、「身份」和「精神」的角度,是不是
- “考研这件事的价值不是那么大,没考上大不了去找工作”
- “我不是技术专家,没有必要深入研究技术”
从更高一层的角度看问题的原因并修复,下一层的问题自然引刃而解
信息流戒断
安小竹的一篇关于信息流戒断的可实操的文章,之前看过一个观点:信息就像糖一样容易上瘾, 信息已经成为现代社会最难以戒除的东西了,所以信息流戒断是非常有必要的
文章提到的一些屏蔽多余信息流的方式(主要是微信,但是其他平台也是类似的)
- 通知:除微信、电话外,屏蔽一切手机 app 通知;卸载掉无用的低频使用的 app,不希望经常看到的在文件夹中折叠起来(比如证券交易软件)
- 微信消息:退出低信息密度群及经常@强打扰的群;所有群聊都免打扰;仅保留3个以内的优质信息群,其他群全部折叠
- 朋友圈:屏蔽掉营销、企业账号或高频分享但不熟的人
- 公众号:取关所有低频使用的账号(招聘、美食店铺、机构号、奇怪应用的官方号等),时效性聚合信息源保留 3 个以内,取关所有为了日更而日更的知识类账号(只有极少极少数能够保证质量的保留),取关所有标题党账号,取关所有未明显标识广告、看到文中文末才发现是软广的账号,极少数几个实用性的工具类账号设置消息免打扰;有所遗漏的,基于推荐流动态设置不接收消息推送
- 屏蔽一切投资、融资、行业报告、宏观经济分析(公众号、社媒账号、群聊等),一个投资机会,如果被信息流推送过来,那大概率是已经过时的(即便有极少数仍然有效的,也需要极高筛选鉴别成本)
工具推荐
- Wasp: 将 React、Node.js、Prisma 结合在一起的全栈开发框架,未来全栈工程师的新选择
- namae: 查询各个平台名字,查询了下 hackthinking 这个名字还没有大规模占用
- namebeta: 查询域名是否被注册以及各大海外平台域名的价格,结合上面的 namae 就能快速找到自己期望的域名,还有一个类似的工具 query.domains
- opengraphexamples: Open Graph Image(OG图像) 集合导航站,OG 图像是用于在社交媒体上分享网页内容时显示的图像,类似于微信分享时的缩略图
有点意思
- 个人制作的三体动画第四集,除了配音是用的广播剧的配音(广播剧也是神作),秒杀异画开天的三体,很难想象这都是一个人完成的
下一篇:vol2. 痛苦是信息